Inside Google Discover : comment 20 pipelines façonnent le flux français
Trois mois de données, 42 millions de cartes. Voici ce que personne n'avait encore mesuré sur l'architecture interne de Google Discover en France.
Ce que vous allez découvrir
Nos données révèlent un système bien plus structuré que ce que la communauté SEO imaginait. Voici les dix découvertes clés — chacune renvoie à sa section détaillée :
- 20+ pipelines distincts — Discover n'est pas un algorithme, c'est un système à couches avec des rôles spécialisés (broadcast, breaking news, tendances, local, social, commercial)
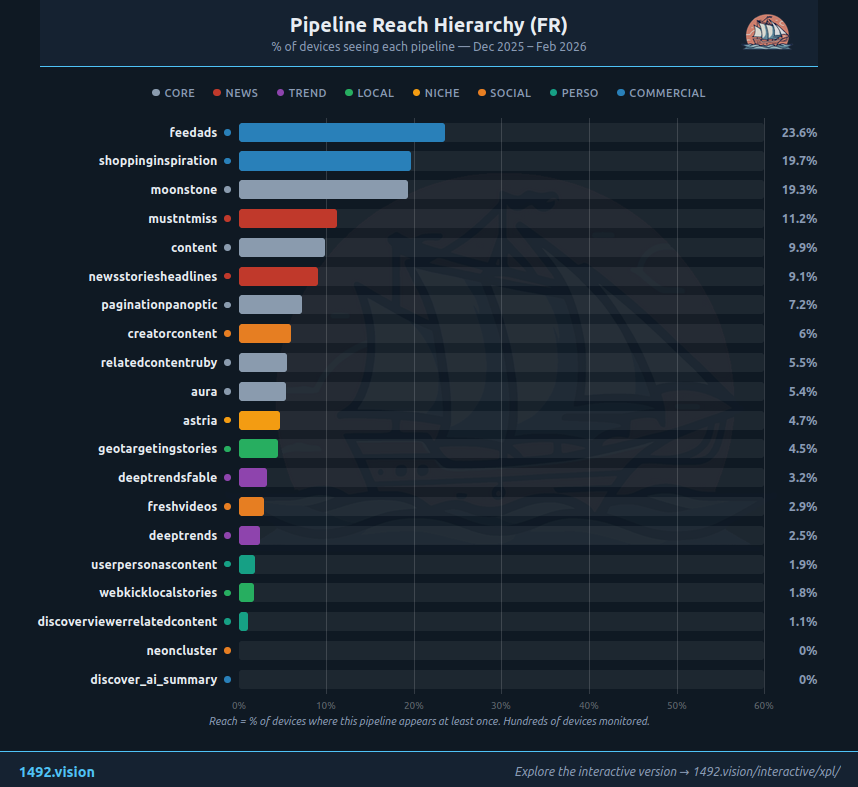
- moonstone : 19,3 % de portée — chaque URL sélectionnée est montrée à près d'1 appareil sur 5. Deux fois plus que le pipeline de base
- mustntmiss : boost de priorité ~2x — le pipeline d'importance éditoriale. Le Monde y domine
- shoppinginspiration : 3,7 jours de durée de vie — 8x plus long qu'un article d'actualité, avec 19,7 % de portée. Mais isolé
- deeptrendsfable → deeptrends — un détecteur de tendances séquentiel à 2 étages, 27 % de taux de passage, +21h entre les deux
- webkicklocalstories : 67 % d'URLs exclusives — un canal dédié à la presse régionale, invisible du reste du système
- creatorcontent : explosion 33x en 3 mois — x.com domine à 73 % en FR, pas YouTube
- 58 % des URLs dans 2+ pipelines — le multi-pipeline est la norme, pas l'exception
- Un système vivant — ~10 pipelines abandonnés, ~8 nouveaux observés. L'architecture évolue en permanence
- La position dans le flux — les pipelines ne sélectionnent pas seulement le contenu, ils contrôlent aussi où il apparaît dans le feed
Méthodologie
Notre analyse repose sur l'observation de flux Discover réels, collectés sur des centaines d'appareils pendant trois mois (décembre 2025 – février 2026). Au total : 42 millions de cartes analysées.
Pour chaque carte Discover, nous avons tracé la pipeline responsable de sa sélection. C'est cette donnée, jamais exploitée à cette échelle, qui permet de décomposer Discover en ses composants. Metehan Yesilyurt a listé certaines de ces pipelines en analysant le SDK Google, la data dévoile plus précisément ce qu'elles sont et surtout comment en tirer parti.
Pour chaque pipeline, nous calculons :
- La portée — pourcentage d'appareils qui voient chaque URL par jour. Un proxy de la puissance de broadcast.
- La vitesse — âge médian des articles au moment de leur apparition. Un proxy de la fraîcheur.
- L'exclusivité — pourcentage d'URLs propres au pipeline, absentes des autres. Un proxy de l'indépendance.
- Le volume — part dans le flux total, exprimée en pourcentage.
Les métriques sont normalisées par la densité d'observation pour éviter les biais liés à la taille de notre panel.
Avant de plonger dans l'analyse complète, explorez visuellement les 20 pipelines : Ouvrir l'explorateur interactif →
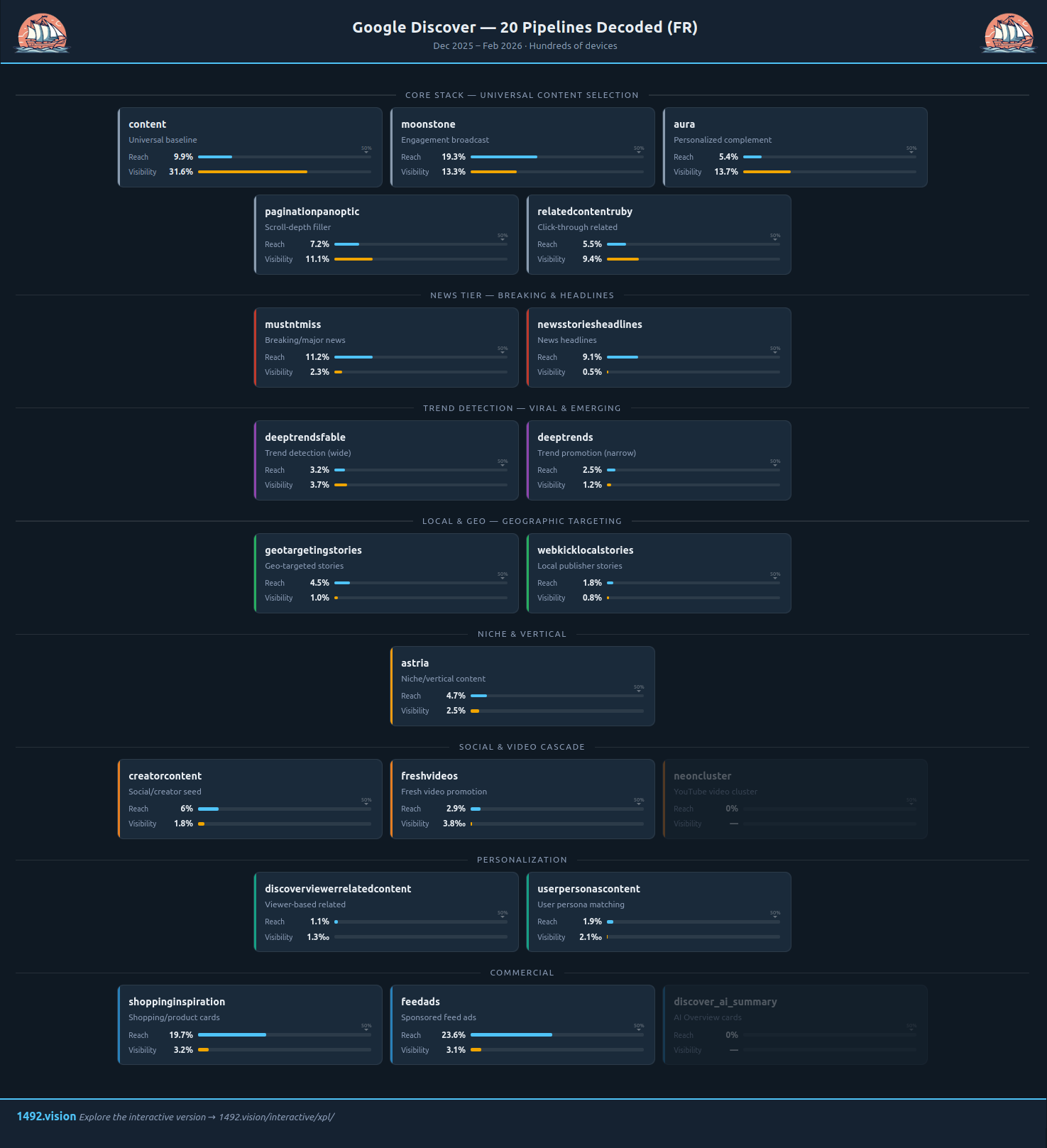
Capture de l'explorateur interactif — vue FR. Version live →
L'architecture : un système à couches
La croyance courante : Discover utilise un algorithme de recommandation qui sélectionne le contenu. La réalité de nos données : Discover est un système structuré en six couches fonctionnelles, chacune avec une logique, une vitesse et une audience distinctes.
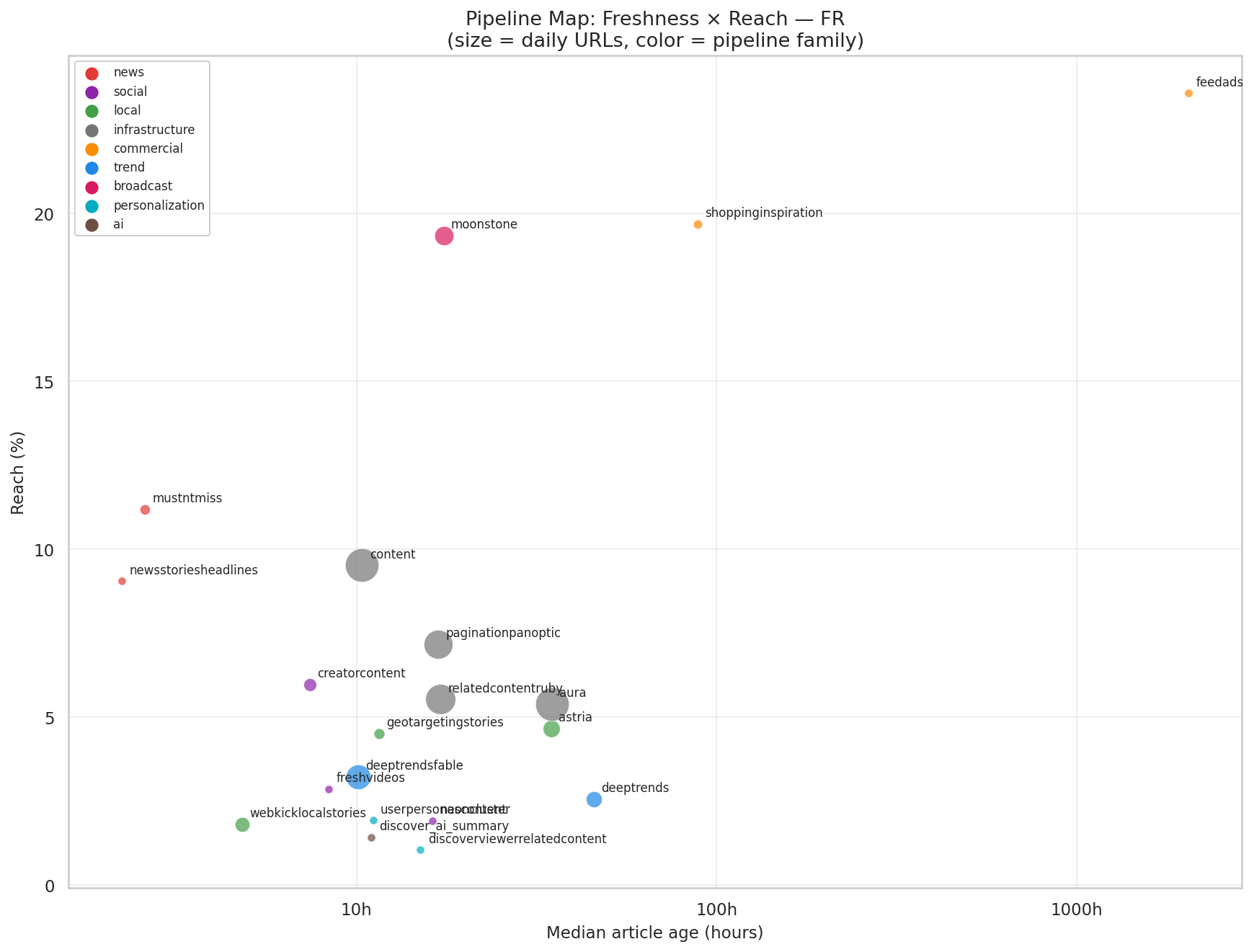
Chaque pipeline positionné par sa vitesse (axe X, log) et sa portée (axe Y). Taille = URLs quotidiennes, couleur = famille fonctionnelle. Les breaking en haut à gauche, les broadcasts au centre, le long-tail en bas à droite.

Le cycle de vie d'un article dans Discover FR : de breaking (nsh 2,2h, mustntmiss 2,6h) à long-tail (shopping 3,7 jours). Chaque pipeline a sa fenêtre temporelle.
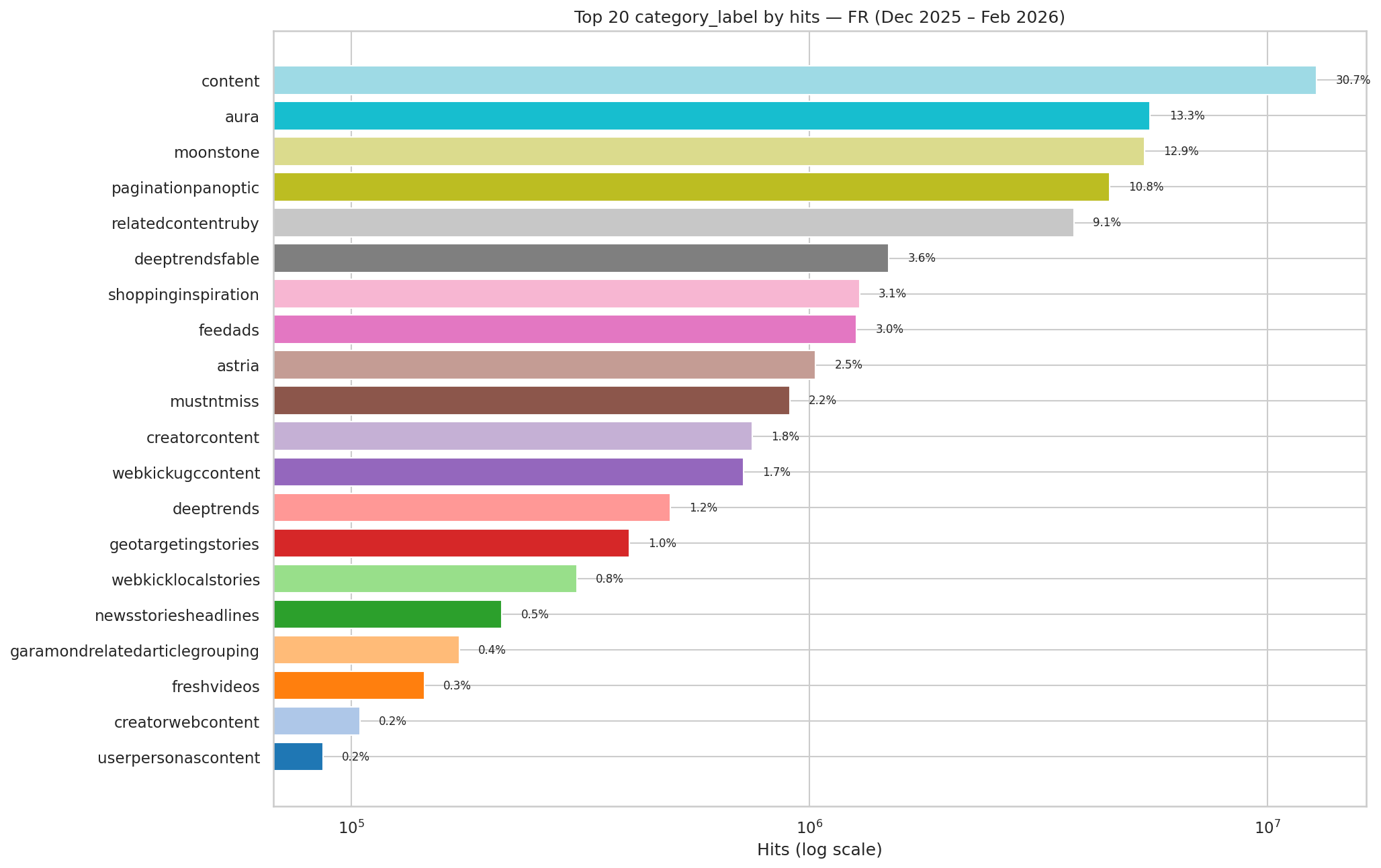
Les 20 pipelines FR classés par volume total (décembre 2025 – février 2026). content domine à 30,7 %, suivi d'aura (13 %) et moonstone (12,9 %).
Couche 1 — Le socle éditorial
Cinq pipelines forment la base de Discover. Ensemble, ils représentent la majorité du volume. C'est une boucle de recyclage : le contenu entre par content, se fait amplifier par moonstone si l'engagement suit, se diversifie via aura, et se prolonge par paginationpanoptic (scroll) et relatedcontentruby (clic).
- content — la baseline généraliste. 9,9 % de portée, 30,7 % du volume FR.
- moonstone — le broadcast d'engagement. 19,3 % de portée — 2x content.
- aura — le diversificateur long-tail. Science, tech, finance. 1,5 jour d'âge médian.
- paginationpanoptic — l'infrastructure de scroll. 7,1 % de portée.
- relatedcontentruby — le contenu lié déclenché par un clic. 5,5 % de portée.
Couche 2 — L'actualité et l'urgence
Deux pipelines gèrent les breaking news et l'importance éditoriale. Ils sont rapides — 2 à 3 heures d'âge médian — et indépendants l'un de l'autre (5 % de recouvrement).
- mustntmiss — l'importance éditoriale. Boost de priorité ~2x. Le Monde domine.
- newsstoriesheadlines — les breaking news. Clusters Google News. 46 % d'URLs exclusives.
Couche 3 — Les tendances
Un pipeline séquentiel à deux étages : deeptrendsfable détecte, deeptrends persiste. 27 % de taux de passage, 21 heures de décalage. x.com est une source de tendances en FR.
Couche 4 — Le local et le géo
Trois approches du local, très différentes :
- geotargetingstories — le contenu mainstream filtré par géolocalisation
- webkicklocalstories — l'hyperlocal pur, 67 % d'exclusivité, presse régionale
- astria — l'autorité locale et lifestyle, avec un délai de 1,5 jour
Couche 5 — Le social et la vidéo
La couche la plus récente et la plus explosive. En FR, c'est x.com qui domine (73 % de creatorcontent), pas YouTube. La cascade creatorcontent → freshvideos → neoncluster fonctionne principalement en anglais.
Couche 6 — Le commercial
Deux écosystèmes séparés du reste :
- shoppinginspiration — le broadcast produit. 19,7 % de portée, 3,7 jours de durée de vie.
- feedads — la publicité. 24,0 % de portée, des campagnes de plusieurs mois.
La dimension cachée : la position dans le flux
Nos données révèlent une dimension que les pipelines contrôlent au-delà de la sélection : l'emplacement dans le feed.
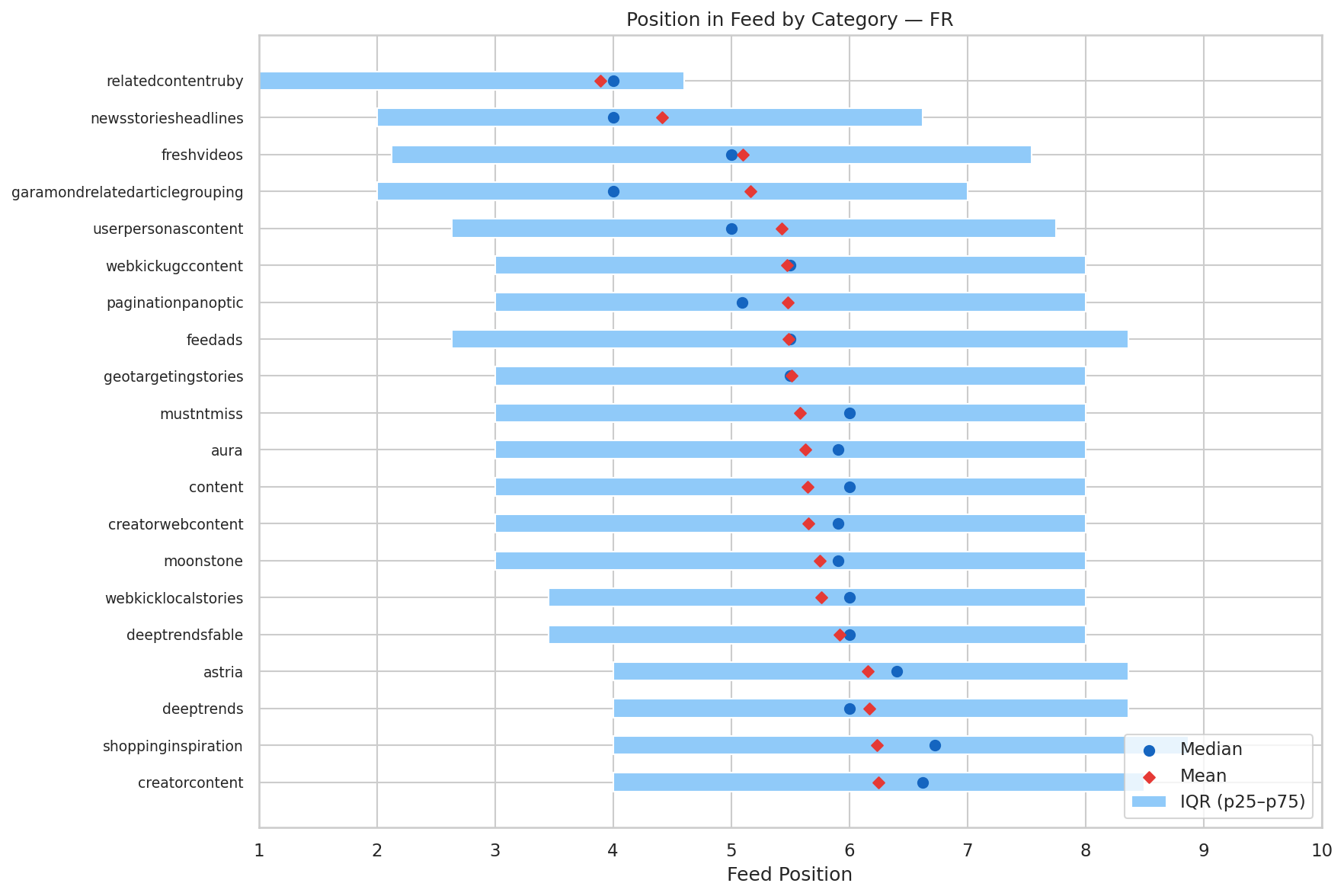
Position médiane et interquartile de chaque pipeline dans le flux Discover. Les breaking news et le contenu lié occupent les positions 2-4 (haut du flux). L'engagement et le shopping sont en positions 6-8 (plus profond).
Les breaking news (newsstoriesheadlines) et le contenu lié (relatedcontentruby) obtiennent un placement premium — positions 2 à 4. L'engagement (moonstone) et les produits (shoppinginspiration) se retrouvent plus profondément — positions 6 à 8. Ce n'est pas aléatoire : c'est un choix d'architecture. Les pipelines urgents captent l'attention immédiate, les pipelines de browse récompensent le scroll.
Pipeline par pipeline — les données FR
Pour chaque pipeline, un profil structuré identique. C'est le corps de cette référence — le détail que vous ne trouverez nulle part ailleurs.
content — la baseline généraliste
- Portée FR : 9,9 %
- Volume : 30,7 % du flux FR — le plus gros pipeline
- Âge médian : 11 heures
- Top domaines FR : YouTube (10,6 %), Le Monde (8,7 %), Le Figaro (7,5 %), L'Equipe (7,3 %), Ouest-France (6,1 %), BFM TV (5,4 %)
- Signal distinctif : le tronc commun. 80 % de recouvrement avec mustntmiss, 65 % avec aura. Tout passe par content — c'est la porte d'entrée du système.
Le pipeline content est l'autoroute principale de Discover. Presque tous les articles le traversent. La question n'est pas d'y arriver — c'est d'en sortir pour atteindre les pipelines spécialisés qui amplifient la portée.
moonstone — le broadcast d'engagement
- Portée FR : 19,3 % — 2x la portée de content
- Volume : 12,9 % du flux FR
- Âge médian : 17,6 heures (0,73 jour)
- Top domaines FR : Ouest-France (9,0 %), BFM TV (8,8 %), Le Figaro (6,8 %), Le Monde (6,2 %), L'Equipe (4,8 %)
- Co-occurrence avec content : 85 %
- Signal distinctif : pool d'URLs restreint (~4,5x moins que content), portée massive. Sélection basée sur les signaux d'engagement.
Moonstone est la machine à broadcast de Discover en France. Il prend une sélection serrée d'URLs et les montre à 2x plus d'appareils que content. C'est la stratégie délibérée du broadcast : peu d'articles, beaucoup d'audience.
Le contenu surreprésenté ? Horoscope (3,5x), paris/jeux (3,3x), divertissement, météo, people. Le profil est clair : moonstone sélectionne ce qui génère du clic.
Et pourtant. Ouest-France — un quotidien régional — domine moonstone. Pas un pure player d'engagement. Le secret : le fait-divers local avec un angle national, la météo, le people régional. Un contenu qui combine ancrage local et résonance nationale.
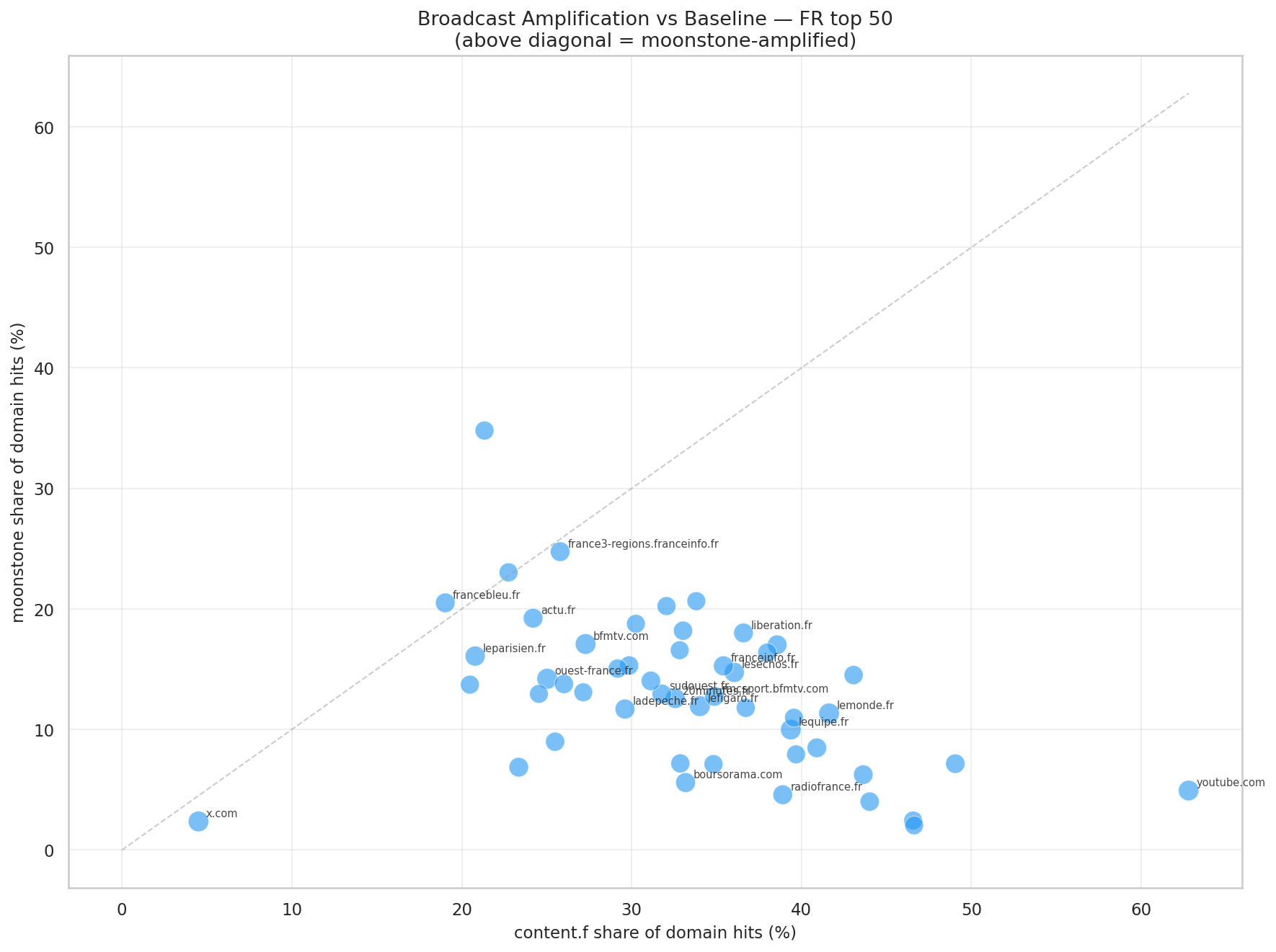
Chaque domaine positionné selon sa part de content (X) et de moonstone (Y). Ouest-France et BFM TV penchent côté moonstone (engagement) ; Le Monde et L'Equipe côté content (autorité). x.com et YouTube sont des outliers — ils n'utilisent pas ces pipelines.
aura — le diversificateur long-tail
- Portée FR : 5,4 %
- Volume : 13,9 % du flux FR — deuxième pipeline en volume
- Âge médian : 1,46 jour — 3x plus ancien que content
- Top domaines FR : distribution large, pas de concentration marquée
- Co-occurrence avec content : 65 %
- Signal distinctif : surreprésentation de la science/tech, business, finance. Contenu plus long (+16 % vs content). Notre hypothèse : sourcing cross-utilisateur — ce qui intéresse les lecteurs similaires à vous.
Aura est l'anti-moonstone. Là où moonstone concentre l'audience sur peu d'articles populaires, aura diversifie : ~3,5x plus d'URLs que moonstone, pour une portée plus modeste. C'est le pipeline qui fait découvrir du contenu que vous n'auriez pas cherché.
Les signaux surreprésentés — business (1,5x), électronique grand public (1,52x), cyclisme (1,42x), rugby (1,33x) — dessinent un profil de curiosité intellectuelle et de niches. Observation intéressante : Trump est spécifiquement sous-représenté dans aura, alors qu'il est omniprésent dans moonstone. Aura filtre le bruit pour faire remonter le signal.
paginationpanoptic — l'infrastructure de scroll
- Portée FR : 7,1 %
- Volume : 11,5 % du flux FR
- Âge médian : 0,69 jour
- Top domaines FR : L'Equipe (11,0 % — #1), Le Monde (9,6 %), Le Figaro (8,9 %), BFM TV (7,0 %), Ouest-France (6,7 %)
- Co-occurrence avec content : 82,6 % — le plus élevé de tous les pipelines
- Signal distinctif : pure infrastructure. Se déclenche quand l'utilisateur scrolle au-delà du premier écran. L'Equipe en #1 s'explique : les fans de sport scrollent profondément.
relatedcontentruby — le contenu lié, déclenché par le clic
- Portée FR : 5,5 %
- Volume : 9,8 % du flux FR
- Âge médian : 0,71 jour
- Top domaines FR : BFM TV (8,5 %), Ouest-France (7,8 %), Le Figaro (7,7 %), L'Equipe (6,0 %), Boursorama (5,1 %)
- Co-occurrence avec content : 73 %
- Signal distinctif : déclenché par le clic utilisateur — pas passif. Quand vous cliquez sur un article, ruby propose du contenu lié au refresh suivant. La présence de Boursorama en #5 est unique — un signal finance qu'on ne retrouve dans aucun autre pipeline.
Le mécanisme seed→expansion est visible dans les données : un clic sur un article politique génère des suggestions politiques au refresh suivant, avec un élargissement progressif du périmètre thématique.
mustntmiss — l'importance éditoriale
- Portée FR : 11,2 %
- Volume : 2,3 % du flux FR — peu de volume, beaucoup de portée
- Âge médian : 2,6 heures (avec une queue de 1-3 jours)
- Top domaines FR : Le Monde (11,3 % — #1), Le Figaro (10,2 %), BFM TV (10,1 %), L'Equipe (8,0 %), 20 Minutes (6,3 %)
- Co-occurrence avec content : 80 %
- Signal distinctif : boost de priorité d'environ 2x dans le système de ranking. Les sujets d'importance — économie (2,98x), politique (2,45x), international (2,23x) — sont surreprésentés. Le lifestyle (recettes, jardinage) en est exclu.
Le fait que Le Monde domine mustntmiss — et non BFM TV, pourtant leader en volume brut — est révélateur. Ce pipeline récompense l'autorité éditoriale sur les sujets d'importance, pas le volume de production.
Notre analyse de scoring suggère un multiplicateur de priorité d'environ 2x pour les articles sélectionnés par mustntmiss. Concrètement : un article dans mustntmiss a deux fois plus de chances d'apparaître en haut de flux qu'un article équivalent dans content seul.
newsstoriesheadlines — les breaking news
- Portée FR : 9,1 %
- Volume : 0,6 % du flux FR — très peu de volume, mais une portée élevée et une fraîcheur extrême
- Âge médian : 2,2 heures
- Top domaines FR : Le Monde (18,8 % — concentration remarquable), BFM TV (9,3 %), Libération (6,4 %), Le Figaro (6,3 %), France Info (5,9 %). Présence suisse notable : 24heures.ch, 20min.ch
- Co-occurrence avec content : 54 % seulement — 46 % d'URLs exclusives
- Signal distinctif : les clusters de stories Google News. Les sujets internationaux (5,2x) et politiques (4,3x) dominent. Le sport — et particulièrement le football — est massivement sous-représenté (50x).
Newsstoriesheadlines est le pipeline le plus indépendant du système. Près de la moitié de son contenu n'apparaît nulle part ailleurs dans Discover. Cela s'explique par son mécanisme : il se connecte aux story clusters de Google News, un système distinct du flux Discover principal.
Le Monde capte près d'un cinquième du volume à lui seul — une concentration remarquable qui reflète son statut de référence pour le breaking news en français.
deeptrendsfable — le scanner de tendances
- Portée FR : 3,2 %
- Volume : 3,8 % du flux FR
- Âge médian : 0,42 jour (10 heures)
- Top domaines FR : Ouest-France (20,4 %), x.com (9,2 % — #2), Le Figaro (8,2 %), BFM TV (7,3 %), La Dépêche (5,4 %)
- Co-occurrence avec content : 65 %
- Signal distinctif : le seul pipeline majeur (après content) avec une présence significative de x.com. Contenus courts (290 caractères médian — les posts x.com font baisser la moyenne). Surreprésentation du voyage (4,8x), tourisme (3,5x), électronique (1,5x).
La présence de x.com en deuxième source est une spécificité française forte. Deeptrendsfable ne détecte pas seulement les tendances dans la presse — il scrute aussi ce qui circule sur le réseau social.
Le nom « FaBLE » renvoie probablement aux embeddings d'intérêts long-terme côté utilisateur (des références publiques dans le code Chromium le suggèrent). L'hypothèse : le pipeline croise les tendances émergentes avec les intérêts stables de chaque utilisateur — ce qui explique la variété thématique observée.
deeptrends — la persistance des tendances
- Portée FR : 2,5 %
- Volume : 1,3 % du flux FR — ~3x moins que deeptrendsfable (le filtre est sévère)
- Âge médian : 1,9 jour — 15,6 % des articles ont 3 à 7 jours
- Top domaines FR : Ouest-France, Le Figaro, BFM TV (même profil que deeptrendsfable, filtré)
- Co-occurrence avec content : 73 %
- Signal distinctif : le deuxième étage du détecteur de tendances. 88 % des URLs partagées apparaissent d'abord dans deeptrendsfable, avec un décalage médian de 21,5 heures. Taux de passage : 27 %. Les 73 % restants sont éliminés.
Le mécanisme séquentiel est clair : deeptrendsfable détecte rapidement (jour 0), deeptrends persiste si le sujet tient (jour 1-2). C'est un filtre de qualité temporel — les tendances éphémères meurent au premier étage, les tendances durables passent au second.
geotargetingstories — le mainstream géo-filtré
- Portée FR : 4,5 %
- Volume : 1,0 % du flux FR
- Âge médian : 11,5 heures
- Top domaines FR : distribution équilibrée — BFM TV, actu.fr, Ouest-France, Le Figaro, Le Monde (tous entre 5 et 7 %)
- Co-occurrence avec content : 72 %
- Signal distinctif : du contenu mainstream filtré par la géolocalisation de l'utilisateur. L'information locale (1,74x), la restauration (1,57x), l'immobilier (1,79x) sont surreprésentés. Ce n'est pas un pipeline hyperlocal — c'est un filtre géographique appliqué au flux général.
webkicklocalstories — l'hyperlocal pur
- Portée FR : 1,8 % (la plus basse)
- Volume : 0,8 % du flux FR
- Âge médian : 4,8 heures
- Top domaines FR : actu.fr (11,0 %), Sud Ouest (9,7 %), Ouest-France (8,6 %), France Bleu (7,8 %), Le Dauphiné (4,2 %), Républicain Lorrain (4,1 %), Le Progrès (3,9 %)
- Co-occurrence avec content : 33 % seulement — 67 % d'URLs exclusives
- Signal distinctif : presse régionale pure. Aucun titre national dans le top 10. Les mots-clés surreprésentés dessinent la carte de la France locale : municipales, maire, commune, élections, et les noms de départements (Loire, Vosges, Rhône, Moselle).
Webkicklocalstories est un canal dédié. Sans lui, les deux tiers de son contenu n'existeraient tout simplement pas dans Discover. Sa portée est la plus faible de tous les pipelines — 1,8 % — mais c'est un choix : le contenu est ciblé géographiquement, donc seuls les utilisateurs de la zone concernée le voient.
Pour la presse régionale, c'est un pipeline existentiel. C'est leur accès direct au flux Discover, indépendant du reste du système.
astria — l'autorité locale et lifestyle
- Portée FR : 4,6 %
- Volume : 2,6 % du flux FR
- Âge médian : 1,5 jour
- Top domaines FR : Ouest-France (16,1 % — domine), Le Figaro (8,1 %), Le Monde (7,2 %), BFM TV (5,3 %), La Dépêche (4,7 %)
- Co-occurrence avec content : modérée
- Signal distinctif : un pipeline de « deuxième jour ». 66 % de ses articles ont entre 1 et 3 jours. Astria attend avant de sélectionner. Profil de contenu atypique : courses hippiques (quinté, Vincennes), astrologie (Rob Brezsny), vin, événements culturels. Anti-sport — le football en est exclu.
creatorcontent — l'intake social
- Portée FR : 6,0 %
- Volume : 1,8 % du flux FR — mais en explosion
- Âge médian : 7,5 heures
- Top domaines FR : x.com (75,0 %), YouTube (5,1 %), Ouest-France (2,5 %), Le Figaro (1,8 %), BFM TV (1,6 %)
- Co-occurrence avec content : 45 % — 55 % de contenu exclusif
- Signal distinctif : en France, creatorcontent est essentiellement un pipeline « ce qui circule sur X ». 75 % de x.com. Le contenu est court — 38 caractères médian (longueur de tweet). Le sport représente 46,8 % du volume — le plus haut de tous les pipelines. Croissance : 33x en 3 mois (décembre → février).
L'explosion de creatorcontent est le fait le plus marquant de notre période d'observation. En trois mois, ce pipeline est passé d'un canal marginal à l'un des plus dynamiques de Discover en France. Et contrairement à l'anglais où c'est YouTube qui domine, c'est le réseau social x.com qui alimente le flux français.
freshvideos — l'amplificateur vidéo
- Portée FR : 2,9 %
- Part du volume FR : 0,3 %
- Âge médian : 8,4 heures
- Top domaines FR : YouTube (53 % du pipeline), TF1 (14,3 %), x.com (12,4 %), L'Equipe (11 %), RTS.ch (6,6 %)
- Signal distinctif : apparaît +15 heures après creatorcontent pour les URLs partagées. En FR, ce n'est pas un pipeline pur vidéo — 47 % d'articles (TF1, L'Equipe) côtoient 53 % de vidéo. La cascade vidéo fonctionne principalement en anglais.
neoncluster — le broadcast YouTube
- Portée FR : quasi nulle (36 hits sur 3 mois)
- Signal distinctif : 100 % YouTube, 100 % anglais. Absent du flux français. En anglais, neoncluster atteint 13 % de portée — un niveau de broadcast — et constitue le troisième étage de la cascade vidéo. Ce pipeline n'existe pas en France.
discoverviewerrelatedcontent — la recommandation de visionnage
- Portée FR : 1,0 %
- Signal distinctif : déclenché par un clic sur un contenu vidéo ou une carte AIO. Croissance notable en anglais (50x), plus modeste en français.
userpersonascontent — les personas utilisateur
- Portée FR : 1,9 %
- Part du volume FR : 0,2 %
- Âge médian : 0,46 jour
- Top domaines FR : Ouest-France (9,7 % du pipeline), BFM TV (9,5 %), Le Figaro (6,4 %), France 3 Régions (4,9 %), Le Monde (4,6 %)
- Signal distinctif : contenu géopolitique en FR — trump, ukraine, iran, guerre, russie, armée sont surreprésentés. Le pipeline utilise un framework de « personas multiples » (Multiple User Representations / MUR) — chaque utilisateur dispose de N profils d'intérêt, et le contenu est apparié au profil pertinent. En déclin : -73 % sur notre période.
shoppinginspiration — le broadcast produit
- Portée FR : 19,7 % (la plus haute portée éditoriale)
- Part du volume FR : 3,3 %
- Âge médian : 3,7 jours — 8x plus long que content
- Top domaines FR : Frandroid (11,7 % du pipeline), Le Parisien (9,3 %), Les Numériques (6,9 %), Ouest-France (6,3 %), BFM TV (5,7 %)
- Co-occurrence avec content : 67 % (33 % exclusif)
- Signal distinctif : le contenu shopping (4,8x), automobile (16,6 %), jeux vidéo (9,3 %) dominent. Surtout : shoppinginspiration est un silo. Très faible co-occurrence avec les autres pipelines. Un test Samsung Galaxy reste dans shopping. Il ne traverse pas vers moonstone, ni mustntmiss, ni deeptrendsfable.
La portée est impressionnante — 19,7 %, la plus haute hors publicité — mais l'isolement est structurel. Pour un éditeur tech/review, le challenge n'est pas d'atteindre shopping (ils y sont déjà), c'est d'en sortir. Ajouter un angle éditorial — une analyse de tendance, un contexte marché — peut ouvrir les portes d'aura et de content.
Portée de chaque pipeline FR (% d'appareils touchés). moonstone en tête à 19,3 %, suivi de shoppinginspiration à 19,7 %. La portée n'est pas proportionnelle au volume.
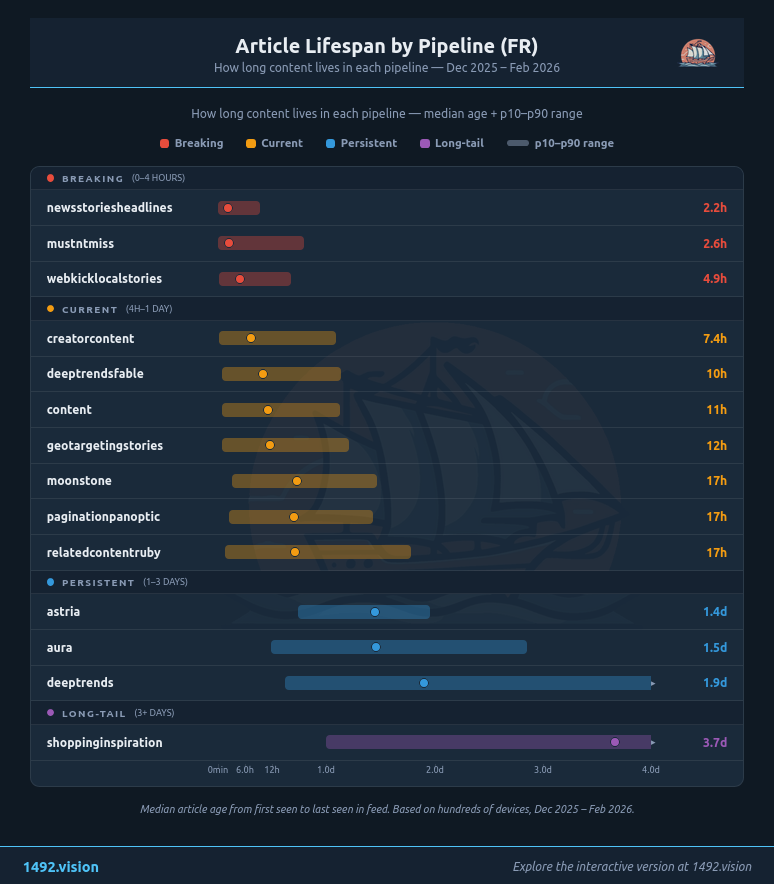
Âge médian des articles par pipeline. De newsstoriesheadlines (2,2h) à shoppinginspiration (3,7 jours). Le contenu produit vit 8x plus longtemps que l'actualité.
feedads — la publicité
- Portée FR : 24,0 % (la plus haute de tous les pipelines)
- Part du volume FR : 3,0 %
- Âge médian : 85,6 jours — des campagnes de plusieurs mois
- Signal distinctif : 100 % publicitaire, 99,8 % d'URLs exclusives. Écosystème totalement fermé. Annonceurs FR : hôtels/voyage (30 %), mode, e-commerce PME, services. Les vidéos publicitaires YouTube représentent 6,7 % des hits. Croissance : 2,7x sur la période.
Feedads est le pipeline le plus puissant en portée brute — un quart de tous les appareils voient chaque publicité. Mais il est hermétiquement séparé du flux éditorial. C'est un canal d'impression publicitaire, pas un canal de contenu.
discover_ai_summary — les résumés IA
- Portée FR : quasi nulle — 72 hits en 3 mois
- Signal distinctif : en anglais, ce pipeline sélectionne du contenu de qualité pour un résumé IA (AI Overview). Reuters, NYT, CNBC, FT, Guardian sont les sources privilégiées. Finance (1,8x), espace (3,4x), sport US (3x) sont surreprésentés. En français : rien. L'AIO n'est pas encore arrivé en France, on le savait déjà via les serps.
Le paysage des domaines FR
Qui domine quels pipelines ? L'empreinte de chaque éditeur raconte une stratégie — qu'elle soit délibérée ou non.
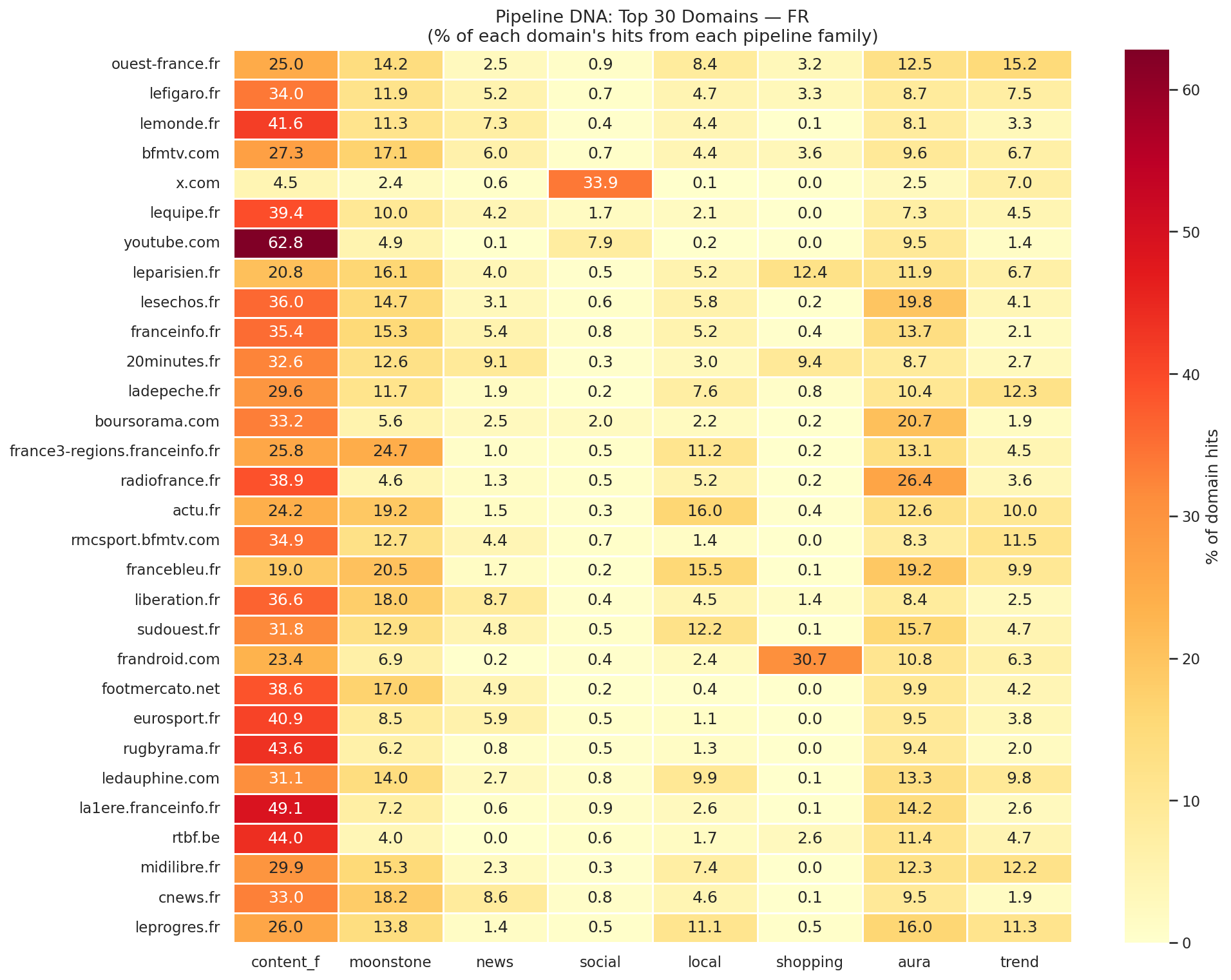
Chaque ligne = un domaine, chaque colonne = une famille de pipelines, couleur = pourcentage des hits. Ouest-France montre un spread équilibré ; Le Monde est concentré sur content et mustntmiss ; x.com éclate la colonne social.
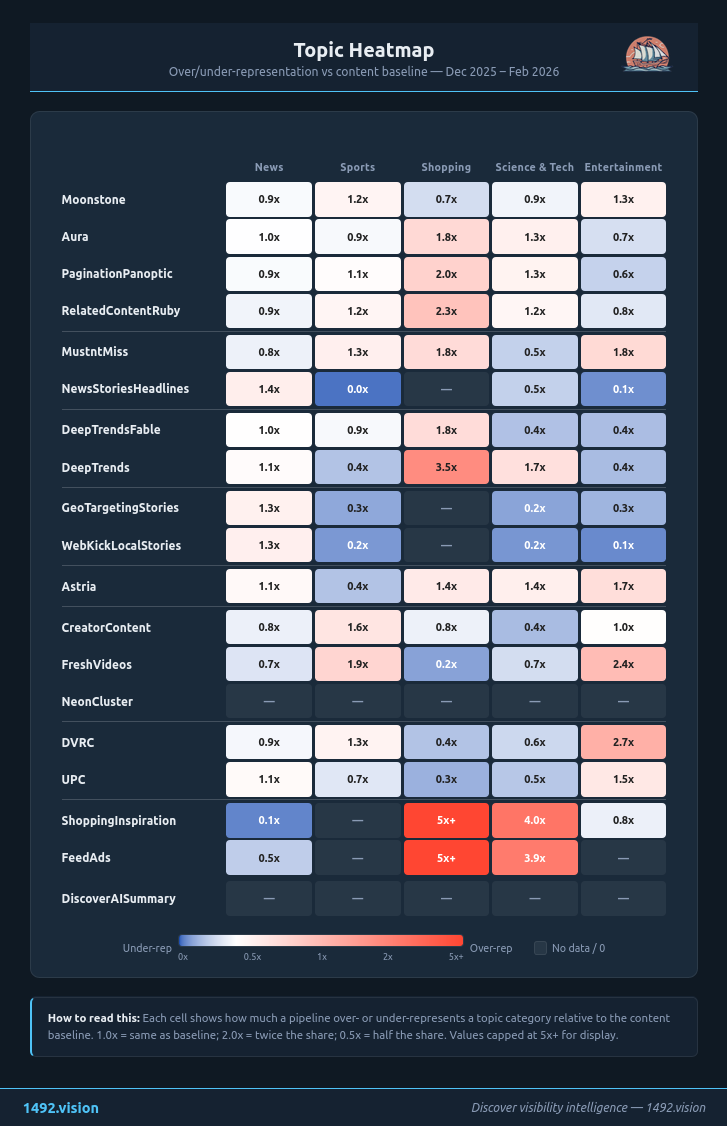
Représentation des sujets par pipeline. Couleur chaude = surreprésentation. moonstone concentre horoscope/people/divertissement ; shopping concentré sur tech/auto ; mustntmiss sur économie/politique/international.
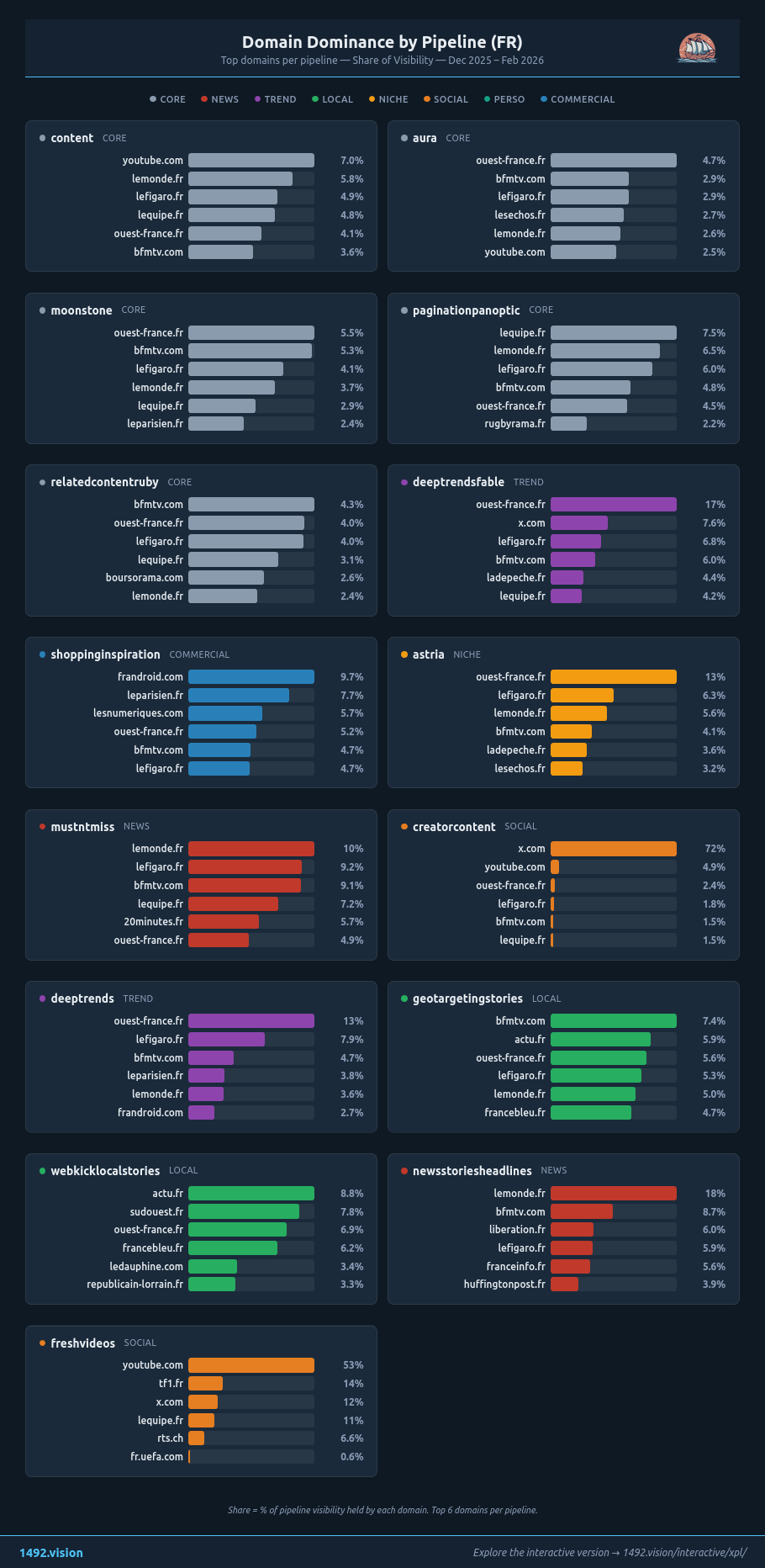
Pour chaque pipeline, les domaines leaders. content : youtube.com, Le Monde, Le Figaro. moonstone : Ouest-France, BFM TV, Le Parisien. mustntmiss : Le Monde, Le Figaro. shopping : Frandroid, Les Numériques.
Ouest-France — le modèle multi-pipeline. #1 dans moonstone, dominant dans webkicklocalstories, top-5 dans astria, deeptrendsfable, geotargetingstories. Son secret : un ancrage régional (qui ouvre les pipelines locaux) combiné à une couverture nationale (qui ouvre les pipelines éditoriaux). Content 25 %, moonstone 14 %, local 8,4 %, aura 12,5 %, tendances 15,2 % — un spread exceptionnel.
Le Monde — l'autorité. #1 dans mustntmiss (11,3 % du pipeline), fort dans content et newsstoriesheadlines. Son empreinte est concentrée : content 41,6 %, le reste réparti entre les pipelines d'urgence et d'autorité. C'est le profil d'un éditeur qui mise sur l'importance éditoriale.
BFM TV — le volume. Fort dans content et moonstone, présent partout en milieu de classement. Absent du top mustntmiss — un signal révélateur sur la perception d'importance éditoriale par le système.
x.com — le réseau social. 73 % de creatorcontent. 33,9 % de la colonne social. x.com n'est pas un éditeur traditionnel, mais en FR, c'est la source dominante du pipeline social de Discover. Un fait que la plupart des stratèges ignorent.
Boursorama — le signal finance. #4 dans relatedcontentruby (5,1 % du pipeline) — un signal unique qu'on ne retrouve dans aucun autre pipeline. La finance a son propre chemin dans Discover, via le clic utilisateur.
Le multi-pipeline : 58 % des URLs FR dans 2+ pipelines
C'est peut-être le finding le plus actionnable de cette étude. La majorité des URLs françaises dans Discover ne sont pas confinées à un seul pipeline — elles traversent le système.
- 42 % des URLs n'apparaissent que dans un pipeline (généralement content)
- 20 % dans deux pipelines
- 13 % dans trois
- 25 % dans quatre ou plus
- Les outliers atteignent 12 à 14 pipelines simultanément
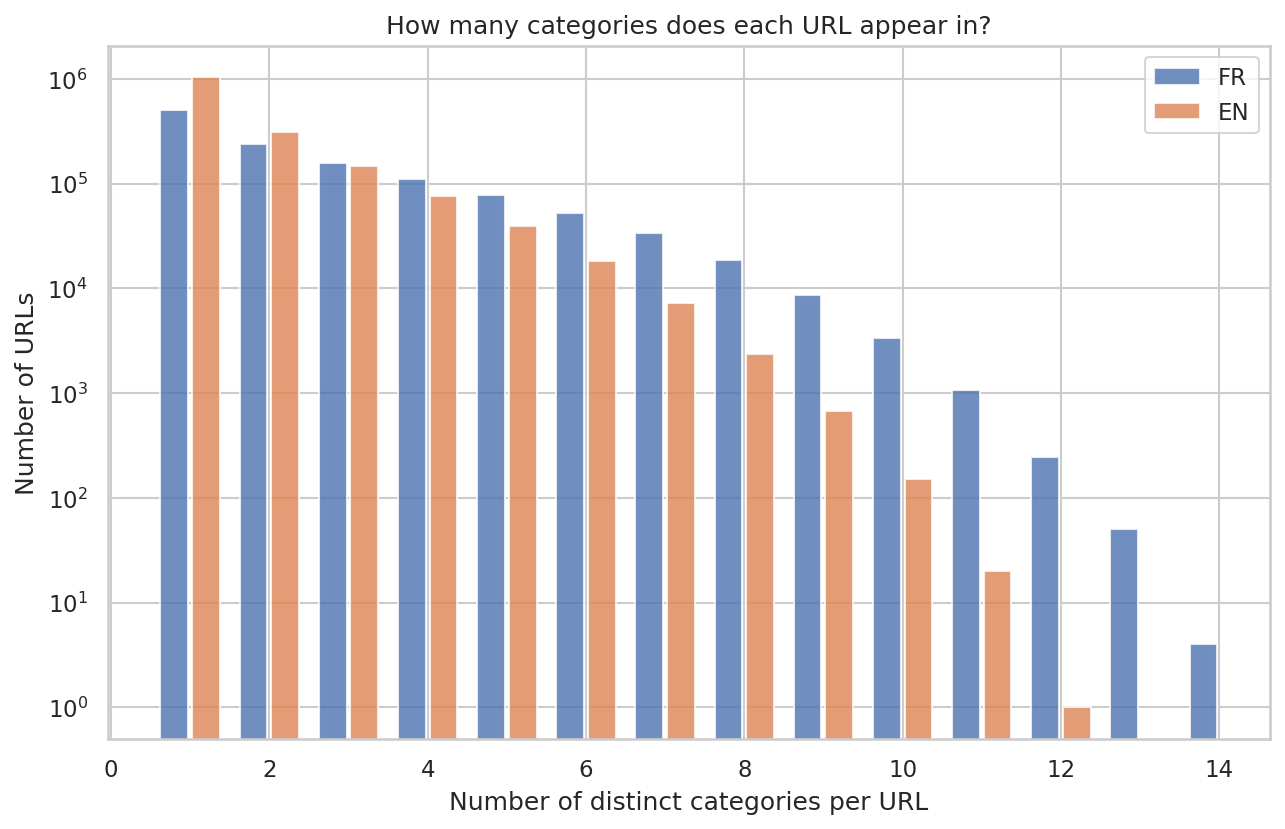
Nombre de pipelines distincts par URL (échelle log). La chute est exponentielle — mais la queue est longue. Certains articles FR atteignent 14 pipelines.
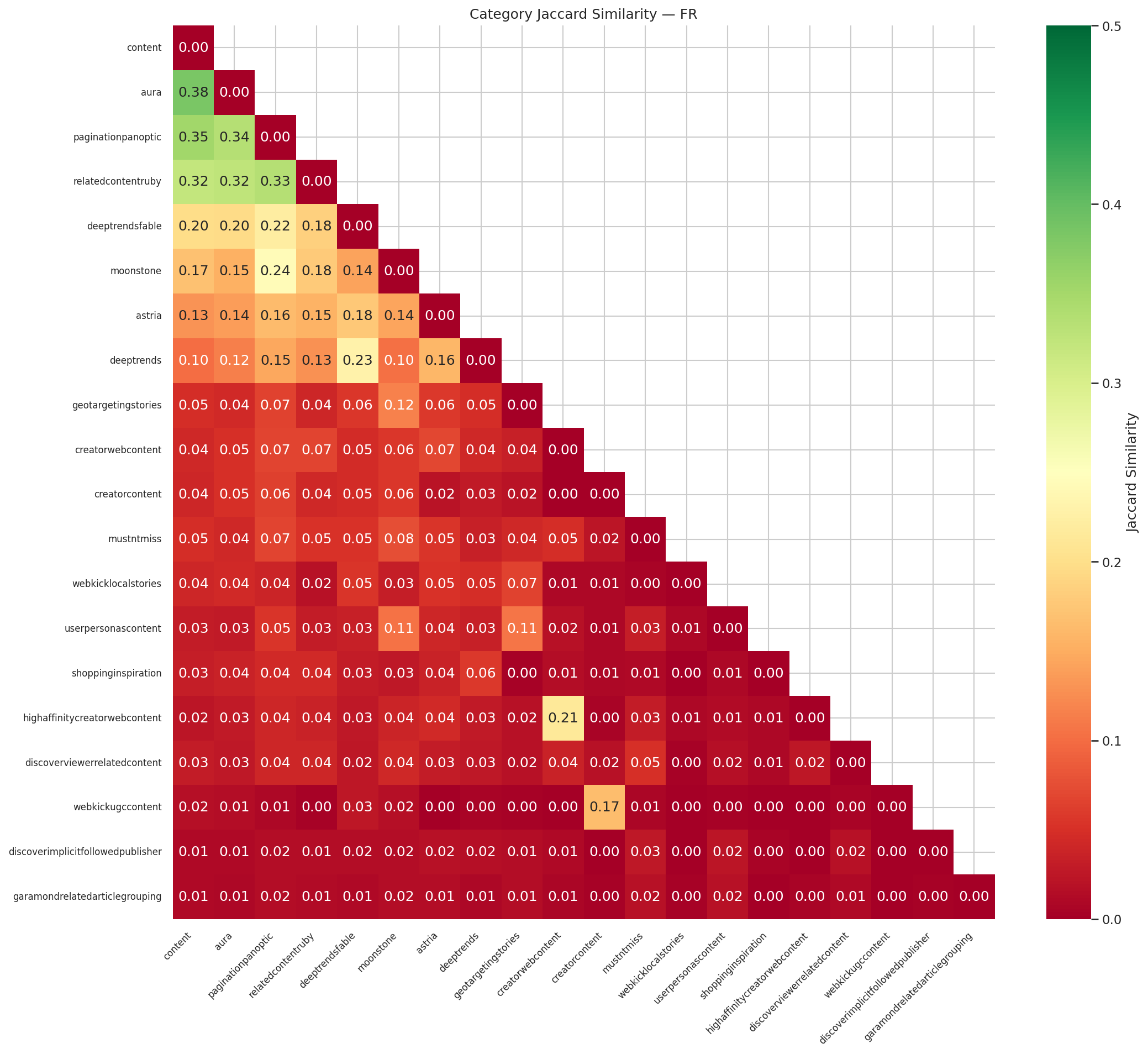
Les paires content-aura (0,38), content-paginationpanoptic (0,35), content-ruby (0,32) forment un bloc chaud — ces pipelines partagent beaucoup d'URLs. Shopping, webkicklocalstories et newsstoriesheadlines forment des rangées froides — des silos structurels.
Ce qui favorise le multi-pipeline : un événement trending (ouvre deeptrendsfable + mustntmiss + content + moonstone), une autorité éditoriale forte (Le Monde atteint 6-8 pipelines là où un site plus petit n'en touche que 2-3), et le double ancrage local/national (le modèle Ouest-France).
Ce qui le bloque : le pur produit (silo shopping), le sport quotidien (confiné à content + moonstone), le lifestyle pur (plafond à 2-3 pipelines), et le contenu ancien (le multi-pipeline est un phénomène des premières 48 heures).
L'analyse complète du multi-pipeline — avec le détail des mécanismes et le scorecard par profil d'éditeur — fera probablement l'objet d'un article dédié sur Réacteur.
Un système vivant
Ce que nous montrons ici est un instantané. Le système Discover évolue en permanence — et nos données en portent la trace.
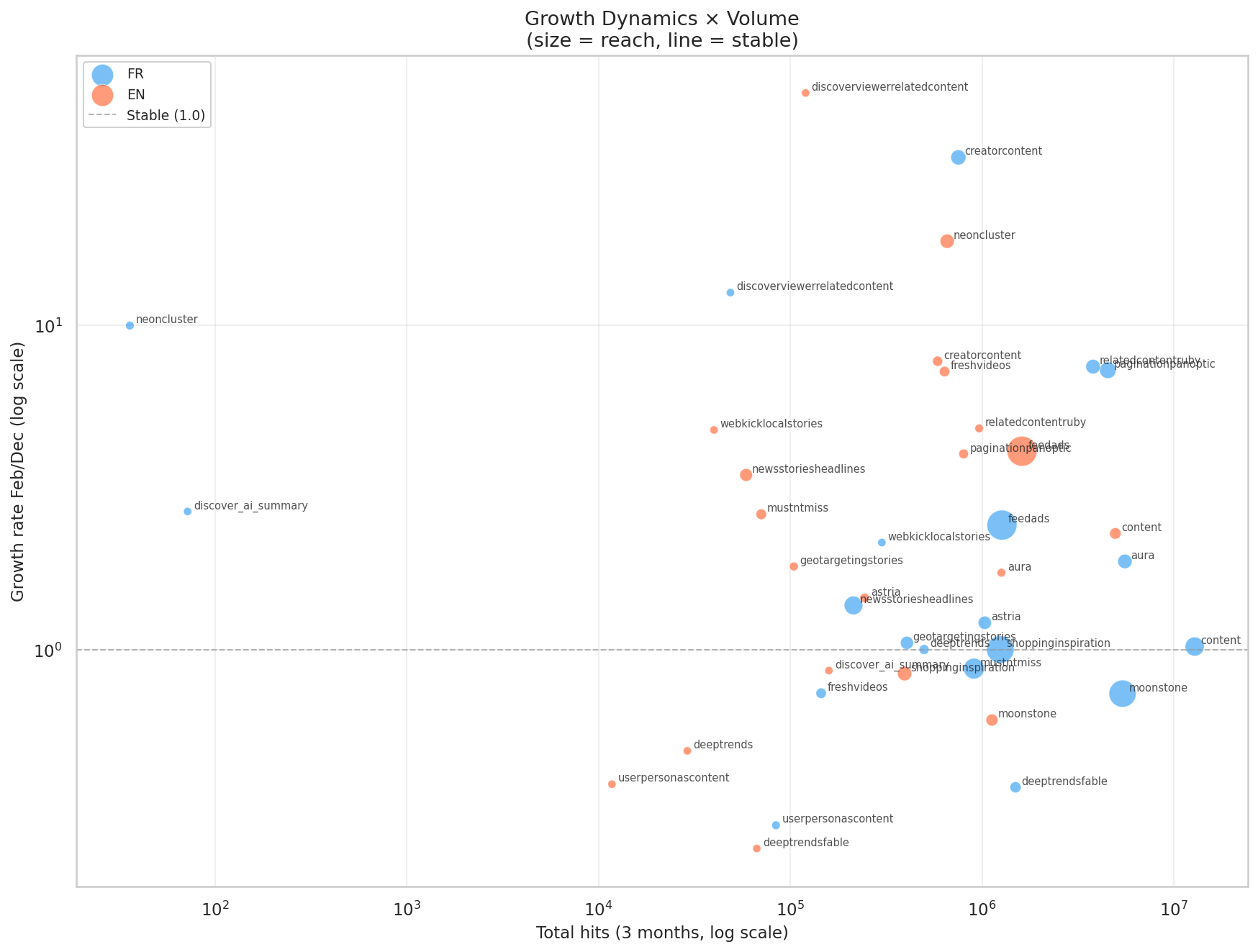
Dynamique de croissance (Y, log) vs volume total (X, log). Au-dessus de la ligne de stabilité = croissance. creatorcontent FR à 33x et discoverviewerrelatedcontent explosent au-dessus. deeptrends et userpersonascontent déclinent. Le système est vivant.
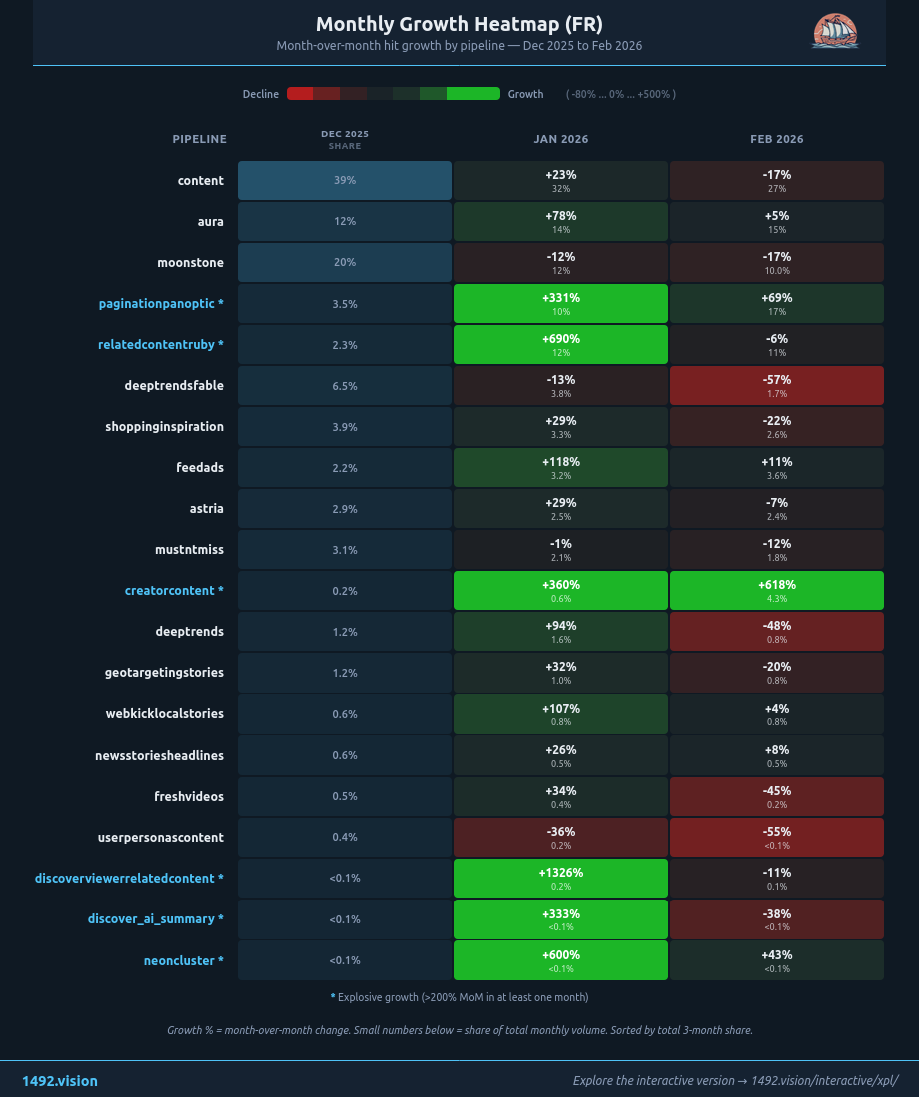
Dynamique mensuelle par pipeline (FR). Les mois en colonnes, l'intensité de couleur représente le taux de croissance. creatorcontent explose de décembre à février ; deeptrends et userpersonascontent se contractent.
Les pipelines qui explosent :
- creatorcontent FR : 33x en 3 mois
- paginationpanoptic : 7x d'expansion
- feedads : 2,7x de croissance publicitaire
Les pipelines qui déclinent :
- userpersonascontent : -73 % — le système de personas semble en retrait
- deeptrends : en contraction
- mustntmiss FR : -17 % (alors qu'il explose en anglais — une divergence intéressante)
Les pipelines disparus :
Une famille entière — les queryrecommendations* (queryrecommendationsmoonstone, queryrecommendationsrelated, etc.) et les clusterprofile* — a été abandonnée. Le nom seul raconte l'histoire : l'ancien système fonctionnait par requêtes et clusters de profils. Le nouveau système fonctionne par embeddings et personas. C'est un changement d'architecture fondamental.
Les pipelines émergents : Nous observons ~8 nouveaux identifiants non encore intégrés dans notre analyse — collaborative filtering, NL tuning, entertainment trailers, garamond (Google Showcase). Le système continue de s'étoffer.
La direction est claire : de query-based vers embeddings/personas, de contenu textuel vers contenu social/vidéo, de sélection passive vers sélection basée sur les signaux d'engagement temps réel. Et l'AIO, aujourd'hui absent de France, ne le restera probablement pas.
Et maintenant ?
Cette carte n'existait pas avant notre étude. Elle change la façon de penser Discover — de « un algorithme, un levier » à « 20 pipelines, 20 leviers différents ».
Chaque profil d'éditeur a des pipelines naturels — ceux que votre contenu atteint par défaut — et des pipelines à conquérir — ceux qui sont accessibles avec des ajustements stratégiques. Un éditeur national atteint 8-12 pipelines. Un site tech/review, 3-5. Un pure player lifestyle, 2-3.
La question n'est plus « suis-je dans Discover ? » mais « dans combien de pipelines suis-je visible ? »
Trois pistes pour aller plus loin :
- Explorer les données — notre explorateur interactif vous permet de naviguer dans les 20 pipelines, comparer les métriques, voir les domaines leaders et les titres typiques
- Suivre la série — chaque semaine, notre newsletter Substack plonge dans un groupe de pipelines avec données, graphiques et recommandations
- Analyser votre domaine — 1492.vision vous donnera prochainement l'empreinte pipeline de votre propre domaine, avec les métriques par pipeline
Le système évolue. Ces données sont un instantané de décembre 2025 à février 2026 — pas une vérité figée. D'où l'intérêt d'un monitoring continu. Comme tout bon capitaine, c'est en naviguant qu'on fait ses meilleures découvertes.
- L'analyse EN complète : 20 pipelines, données anglaises, cascade vidéo, AIO, EPL
- L'analyse comparative FR/EN : Les particularités de chaque marché
Données : 42 millions de cartes Discover, décembre 2025 à février 2026. Analyse : 1492.vision. Les mécanismes internes sont présentés comme nos interprétations basées sur les données observées et la recherche publique disponible.
Authors
Posted on 2026-03-28