Intégrer la donnée : un usage de l'Open Knowledge Format que Google n'a pas illustré
1. La promesse que tout le monde a lue
En juin 2026, Google Cloud a publié l'Open Knowledge Format (OKF) : une façon ouverte et neutre de partager de la connaissance sous forme d'un répertoire de fichiers markdown avec un prélude YAML, livrable en une archive. Un seul champ obligatoire, des liens non typés, pas de SDK, pas de runtime. L'annonce le cadre autour du partage de connaissance entre équipes et organisations, et cite les playbooks, runbooks, métriques et API comme concepts valides. À la lecture de l'annonce, ça sonne comme un format d'échange de données : une langue commune pour passer du savoir d'une partie à une autre.
(Ce n'est pas la lecture SEO. OKF n'est pas un levier de référencement ni un truc à base de
llms.txt, et j'ai expliqué pourquoi dans un précédent article.
Ici, on parle de ce qu'on en a fait.)
2. Le filtre de la réalité
L'annonce a déclenché une vague de réactions rapides, le plus souvent une paraphrase du communiqué. Moins de gens ont ouvert le dépôt et ont vraiment construit quelque chose avec (Marie Haynes en fait partie). Chez 1492, on voulait se servir du format, pas le résumer, alors on est partis de là où la prose s'arrête.
Lisez les bundles de référence, pas la prose, et le tableau se resserre.
Les exemples livrés (GA4, Stack Overflow, Bitcoin) et l'agent d'enrichissement font tous la même
chose : ils décrivent des tables BigQuery. Le schéma, le sens d'une colonne, les chemins de
jointure, et un champ resource qui pointe vers la donnée, là où elle se trouve. La donnée ne
voyage jamais. Un concept qui décrit une table, c'est en pratique un skill : de la métadonnée,
une grille de lecture pour un agent qui a déjà accès à l'entrepôt. Pour le dire crûment, le bundle
de référence est une couche d'annotation, un joli nom pour un skill posé sur des données que le
producteur garde, pas la donnée elle-même.
C'est réellement utile, et c'est un usage légitime du format. Mais c'est à un pas de la promesse de l'annonce. La prose dit partager la connaissance entre organisations ; la référence montre décrire mes propres tables privées pour des agents externes. Le pointeur suppose que le lecteur peut le suivre. Reste une question que les exemples n'abordent pas : et si le lecteur ne peut pas atteindre votre entrepôt, et si la connaissance qui vaut d'être partagée c'est la data en elle même ?
3. Le geste : mettre la donnée à l'intérieur
OKF n'exige qu'un seul champ sur un concept, un type, et laisse le reste au producteur. Rien ne
dit qu'un bundle doive se limiter à un catalogue de pointeurs. Alors on a fait ce que les exemples de
référence n'illustrent pas : on a intégré la donnée à l'intérieur du bundle.
Pas de pointeur resource, pas de requête à l'autre bout. Le bundle est le livrable. Trois
propriétés en découlent, et c'est bien tout l'enjeu :
- Atomique. La donnée et la façon de la lire voyagent ensemble. Rien à synchroniser, rien qui dérive sous vos pieds, et ça marche hors ligne. Là où la référence Google annote une table qu'elle garde, notre bundle est la donnée plus la façon de la lire, en un seul artefact autonome.
- Possédé. C'est un artefact ouvert, lisible par un humain, non propriétaire, que le client garde, archive, versionne et compare, par lui-même, même après la fin de toute mission.
- Mutuellement utile. On partage une vraie analyse sans donner accès à la base ; le client reçoit un actif portable plutôt qu'un PDF figé et les conclusions de quelqu'un d'autre.
Le même format, la moitié de sa raison d'être (de la connaissance sélectionnée, partagée) que les exemples n'ont pas montrée.
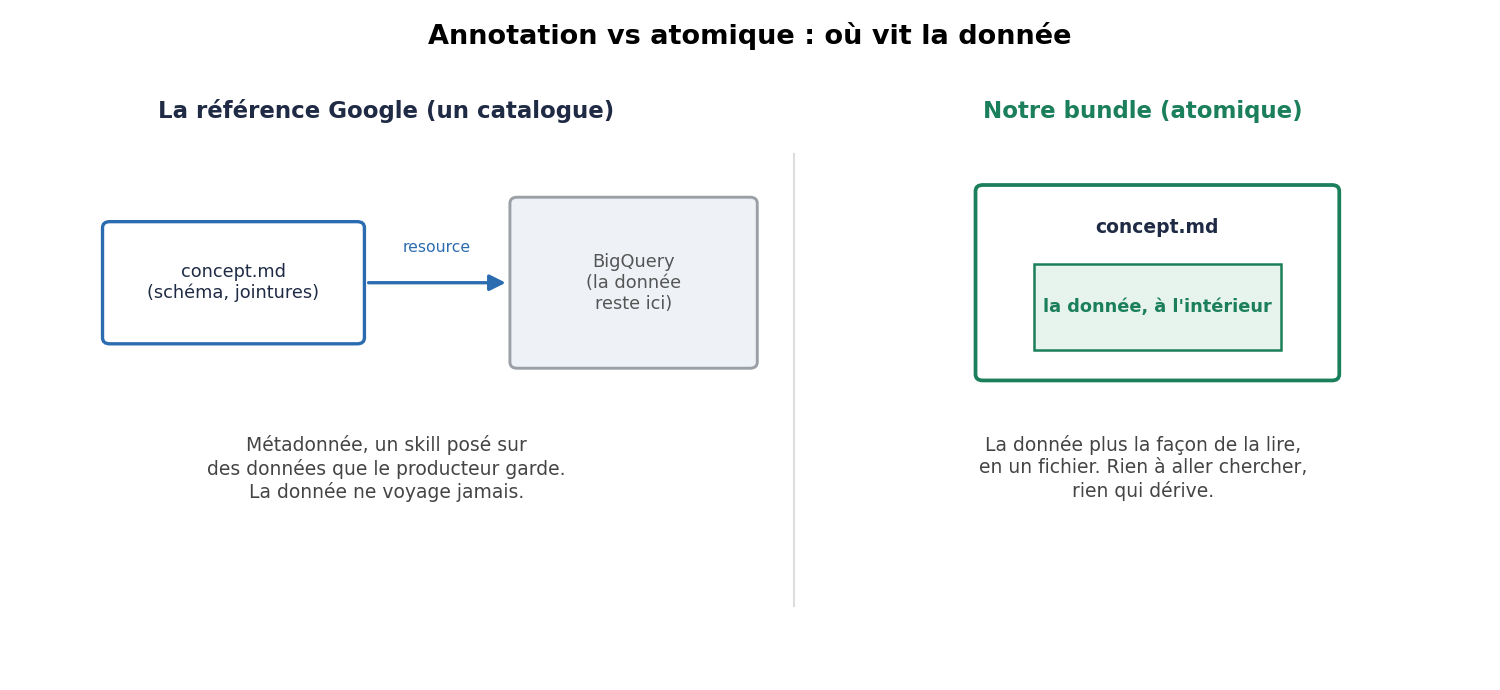
Où vit la donnée. La référence Google décrit une table et pointe vers elle ; notre bundle, c'est la donnée plus la façon de la lire, en un seul fichier.
4. Ce qu'on a construit
Le producteur est un petit script déterministe. Aucun agent, aucun modèle dans la boucle, par choix : la génération est reproductible et auditable, ce qui, pour un livrable qui quitte nos mains, est l'essentiel. Il lit notre réplica analytique et sérialise par exemple l'empreinte Google Discover d'un site, plus des analyses soigneusement choisies, dans un bundle autonome par site et par période.
Trois choses voyagent ensemble dans ce bundle :
- La donnée. Les topics et entités du site, son mix de pipelines et la façon dont ce mix évolue, et ses meilleurs articles, chacun portant la performance sous forme de score normalisé (0 à 100) et d'un signal de persistance, les jours en feed, plus des parts et des distributions. La performance, c'est le score et les jours, jamais les hits, à dessein : les hits sont ce que capte notre flotte de capture, pas du trafic, et un livrable qui quitte nos mains ne doit jamais laisser confondre l'un pour l'autre.
- Les playbooks. Chacun est lui-même un concept OKF, et chacun est un skill : il dit à un agent lecteur comment mener une analyse précise sur un ou plusieurs bundles. La symétrie est jolie. Les concepts de Google sont des skills qui décrivent une donnée qu'il garde ; les nôtres sont des skills livrés à côté de la donnée sur laquelle ils opèrent.
- Les guardrails. Un concept, lu en premier, qui énonce comment les chiffres peuvent et ne peuvent pas être lus : des parts de visibilité avec score et jours, jamais du trafic ; les entités comme axe fiable et les topics auto-classés seulement indicatifs ; l'entité de marque du site est une auto-référence et elle est écartée. Le contrat de lecture voyage avec la donnée.
Deux choix d'ingénierie le rendent exploitable à l'échelle : un bundle complet pèse quelques centaines de kilo-octets de markdown, assez léger pour en déposer plusieurs dans le contexte d'un agent d'un coup ; ensuite la méthode (les playbooks) et la donnée peuvent voyager ensemble ou être livrées séparément, pour qu'un client qui charge beaucoup de bundles ne trimballe pas dix fois les mêmes recettes.
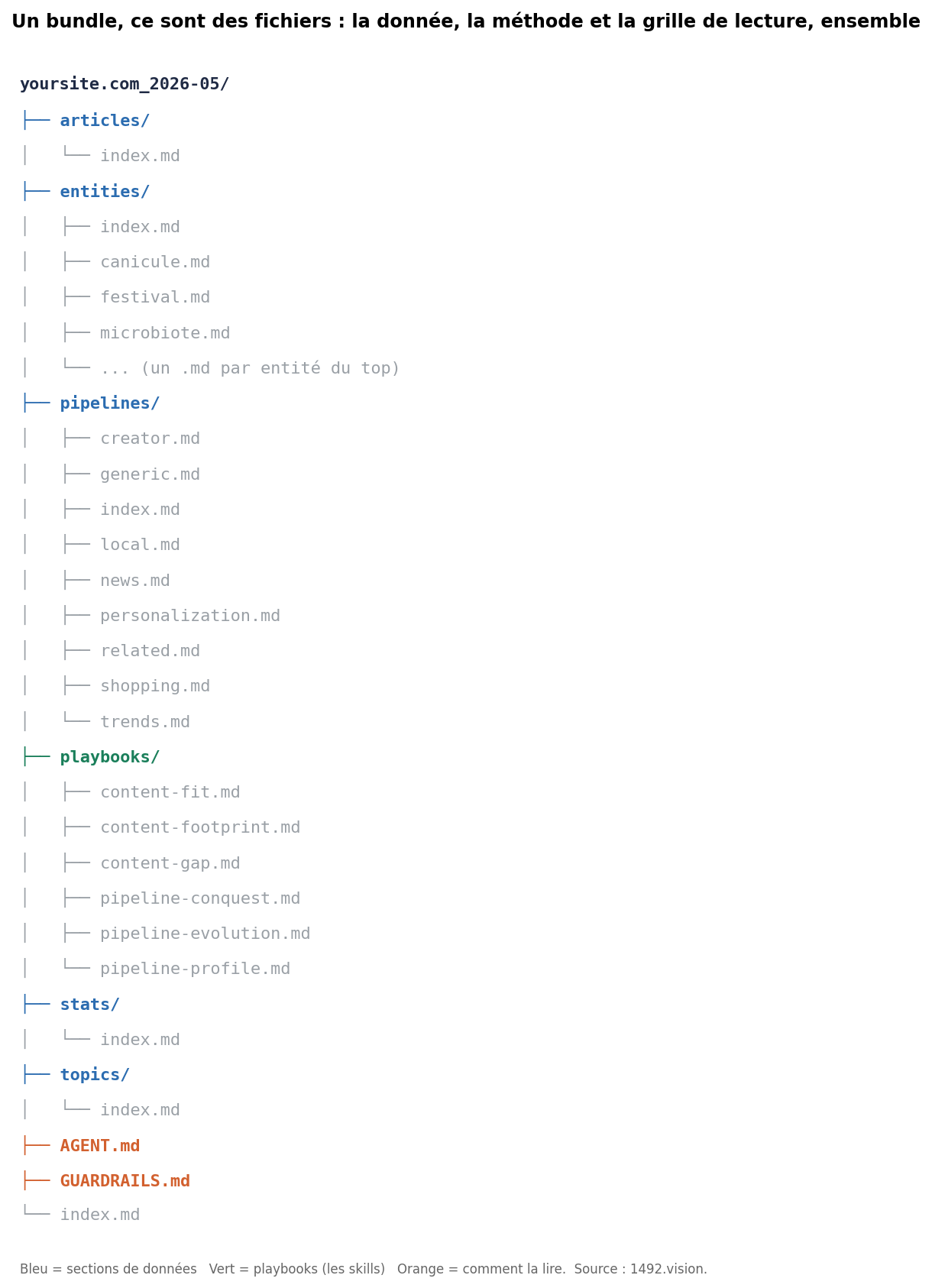
Un bundle, ce sont des fichiers : les sections de données, les playbooks (les skills) et le contrat de lecture GUARDRAILS, dans un seul dossier.

Dans un fichier concept : un peu de prélude YAML, puis la donnée en table markdown classée. La performance, c'est le score et les jours, jamais les hits.
5. Ce que le client peut en faire
Un bundle n'est pas que de la donnée : il embarque les recettes pour la lire. L'agent choisit le playbook qui correspond à la question et produit la réponse lui-même.
Se connaître, à partir d'un bundle :
- pipeline-profile : quels mécanismes du feed vous portent, et quel profil d'éditeur vous êtes.
- content-footprint : sur quoi vous êtes visible, et quelles veines décrochent vos pics, pas seulement votre volume.
- pipeline-evolution : comment ce mix se déplace dans le temps.
Agir face aux concurrents, à partir de deux bundles ou plus de la même période :
- content-gap : où un concurrent est devant, et quoi publier pour combler.
- content-fit : lesquels de ses succès sont un fit naturel pour vous, avec des idées de titres dans votre propre voix.
- pipeline-conquest : quels pipelines menés par un concurrent vous pouvez réalistement prendre.
Quelques résultats se détachent, esquissés ici et déroulés en entier dans l'article de cas d'usage qui l'accompagne :
- La veine qu'un rédacteur n'aurait pas cherchée. À partir de deux bundles et du playbook content-fit, un agent a fait remonter une veine durable à fort score qu'un concurrent gagne et que la cible touche à peine, classée par performance plutôt que par volume, puis a proposé des titres dans la voix de la cible et écarté les succès hors de son territoire. Du fit, pas de la copie.
- Deux questions, deux réponses. Le même bundle concurrent répond différemment à « où suis-je en retard ? » et « qu'est-ce qui me correspond naturellement ? », et les coups les plus durables sont à l'intersection.
- Dominer un sujet n'est pas gagner. Un site qui dominait un sujet par pur volume avait pourtant la traîne la plus plate de son panel, parce qu'il répétait un seul gabarit ; classer ses propres articles par score a exposé le plateau d'un coup d'œil.
- La diffusion a un plafond. Le mix de mécanismes qui portent un site voyage aussi dans le bundle : un site s'appuyait sur un canal géociblé à faible plafond pendant que sa portée par intérêt s'érodait, là où le concurrent nourrissait le canal durable avec du contenu qui score.
Et au-delà des playbooks : le rapport revient dans n'importe quelle langue que porte la donnée, le bundle s'affiche en graphe dans le visualiseur OKF de Google, et vous pouvez y verser votre propre donnée (la Search Console, par exemple), forker les playbooks, et poser des questions qu'on n'avait pas anticipées. Et le client peut continuer à bâtir dessus : plus de données, plus de contexte, ses propres playbooks, posés par-dessus ce qu'on livre.
Des recettes, pas des résultats. L'agent les exécute ; les conclusions restent les vôtres.
6. Ce qu'on a testé, et où ça s'arrête
Un bundle qui quitte nos mains ne vaut quelque chose que s'il est vraiment autonome, alors on a vérifié. On a confié à un agent neuf rien d'autre que les bundles : aucun accès à notre base, aucun outil interne, aucun analyste dans la boucle. Il a lu les guardrails en premier, choisi le bon playbook, produit une vraie analyse de gap, et respecté les règles de lecture tout seul : il a repéré l'auto-référence du masthead et rebasé les parts, il a fait confiance aux entités plutôt qu'aux labels de topics bruités, et il n'a jamais transformé une part en chiffre de trafic. La connaissance était dans le bundle, pas en nous. C'était ça qu'il fallait prouver, et ça a tenu.
Il importe tout autant de dire ce que le bundle ne fait pas. C'est un instantané de période : il ne voit pas la volatilité quotidienne (la météo au jour le jour du feed), et il n'isole pas seul l'avant-après d'une mise à jour Google précise : les deux demandent une granularité temporelle qu'un seul instantané ne porte pas (une série de bundles dans le temps, en revanche, le peut). Et il ne dit rien en absolu : pas de trafic, pas d'audience, pas de portée. Ce sont des parts et des scores d'échantillon de capture, pas des analytics GSC, par choix de conception et de source (le client peut ajouter un bundle de données GSC en complément).
7. Conclusion
Google a cadré OKF autour du partage de connaissance entre organisations et l'a livré comme un catalogue sur des données que vous gardez, ou plutôt que Google garde pour vous. On a pris le même format et utilisé la moitié qu'il n'a pas illustrée : le bundle est la donnée, curée et prête, pour un lecteur qui ne devrait pas avoir à atteindre notre entrepôt.
OKF est un format ouvert et large de Google Cloud. L'usage catalogue est le sien ; l'usage donnée-embarquée est le nôtre, un choix de producteur que la spec autorise explicitement, pas un style béni par Google.
Un statut honnête, et comment en obtenir un. C'est un proof of concept. C'est expérimental, ça va continuer d'évoluer, et c'est déjà utilisable aujourd'hui. Si vous êtes client, vous pouvez demander un bundle de votre propre empreinte, et celle de vos concurrents sur la même fenêtre, dans le cadre de la mission. Sinon, on peut quand même en produire un pour un host et une plage de dates donnés, contre rémunération : sans engagement, à vous de le garder et de le lire avec l'agent que vous voulez.
On ne mise pas tout dessus. On l'a construit parce que le format rendait l'essai peu coûteux, et on le met entre les mains des gens pour apprendre ce qu'ils en font. La demande donnera le cap : si ça s'avère utile, ça devient une part durable de ce qu'on livre ; sinon, ça reste l'expérience que c'est. Dans tous les cas, la donnée finit entre vos mains, et la direction que vous lui donnez, c'est vous qui la choisissez.
À lire aussi. Les quatre cas d'usage en détail : l'article de cas d'usage qui l'accompagne Les bundles de données OKF en pratique : quatre cas d'usage. Le fond sur pourquoi OKF n'est pas un levier de search (en anglais): "Google just shipped a format that admits the model can read".
Authors
Posted on 2026-06-25