Putting the data inside: an Open Knowledge Format use Google did not illustrate
1. The promise everyone read
In June 2026 Google Cloud published the Open Knowledge Format (OKF): an open, vendor-neutral way to share knowledge as a directory of markdown files with a little YAML frontmatter, shippable as a tarball. One required field, untyped links, no SDK, no runtime. The launch framed it around sharing knowledge across teams and organizations, and named playbooks, runbooks, metrics, and APIs as valid concepts. Read the announcement and it sounds like a data-exchange format: a common tongue for handing knowledge from one party to another.
(This is not the SEO reading. OKF is not a ranking lever or an llms.txt trick, and I argued
why in a previous piece.
This one is about what we built with it.)
2. The reality check
The launch drew a wave of quick takes, most of them a paraphrase of the announcement. Fewer people opened the repository and actually built something with it (Marie Haynes is one who did). We wanted to use the format, not summarize it, so we started where the prose stops.
Read the reference bundles, not the prose, and the picture narrows.
The shipped examples (GA4, Stack Overflow, Bitcoin) and the enrichment agent all do the same
thing: they describe BigQuery tables. The schema, the meaning of a column, the join paths,
and a resource field that points at the data where it lives. The data never travels. A
concept that describes a table is, in practice, a skill: metadata and a reading guide for
an agent that can already reach the warehouse. Put bluntly, the reference bundle is an
annotation layer, a fancy name for a skill over data the producer keeps, not the data itself.
That is genuinely useful, and it is a fair use of the format. But it sits a step away from the announcement's promise. The prose says share knowledge across organizations; the reference shows describe my own private tables for external agents. The pointer assumes the reader can follow it. Which leaves a question the examples do not answer: what if the reader cannot reach your warehouse, and the knowledge worth sharing is the curated result itself?
3. The move: put the data inside
OKF requires exactly one field on a concept, a type, and leaves the rest to the producer.
Nothing says a bundle has to be a catalog of pointers. So we did the thing the reference
examples do not illustrate: we put the curated data inside the bundle.
No resource pointer, no query on the far side. The bundle is the deliverable. Three
properties follow, and they are the whole point:
- Atomic. The data and the way to read it travel together. Nothing to synchronize, nothing that drifts underneath you, and it works offline. Where Google's reference annotates a table it keeps, our bundle is the data plus the way to read it, in one self-contained artifact.
- Owned. It is an open, human-readable, non-proprietary artifact the client keeps, archives, versions, and compares, on its own, even after any engagement ends.
- Mutually useful. We share real insight without handing over database access; the client gets a portable asset instead of a frozen PDF and somebody else's conclusions.
Same format, the half of its purpose (curated knowledge, shared) that the examples happened not to show.
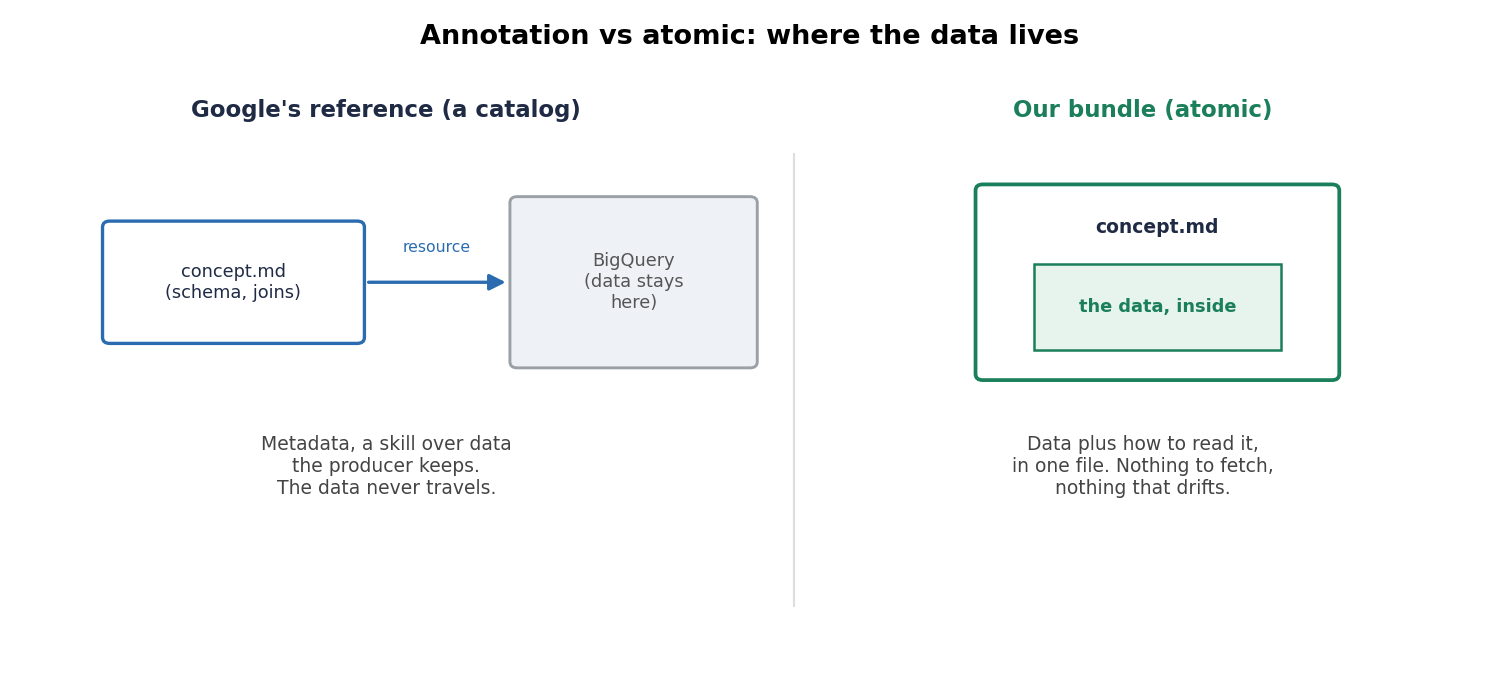
Where the data lives. Google's reference describes a table and points at it; our bundle is the data plus how to read it, in one file.
4. What we built
The producer is a small deterministic script. No agent, no model in the loop, by design: the build is reproducible and auditable, which for a deliverable that leaves our hands is the point. It reads our analytics replica and serializes a website's Google Discover footprint and carefully chosen analytics into one self-contained bundle per site and period.
Three kinds of thing travel together in that bundle:
- The data. The site's topics and entities, its pipeline mix and how that mix is moving, and its top articles, each carrying performance as a normalized score (0 to 100) and a days-in-feed persistence signal, plus shares and distributions. Performance is score and days, never hits, on purpose: hit counts are what our capture fleet sees, not traffic, and a deliverable that leaves our hands must never let one be read as the other.
- The playbooks. Each is itself an OKF concept, and each is a skill: it tells a reading agent how to run one specific analysis over one or more bundles. The symmetry is the nice part. Google's concepts are skills that describe data it keeps; ours are skills shipped next to the data they operate on.
- The guardrails. One concept, read first, that states how the numbers may and may not be read: visibility shares with score and days, never traffic; entities are the reliable axis and auto-classified topics only indicative; the site's own brand entity is a self-reference and gets dropped. The reading contract travels with the data.
Two engineering choices keep it usable at scale: a full bundle is a few hundred kilobytes of markdown, small enough to drop several into one agent's context at once; plus the method (the playbooks) and the data can travel together or ship separately, so a client loading many bundles is not carrying the same recipes over and over.
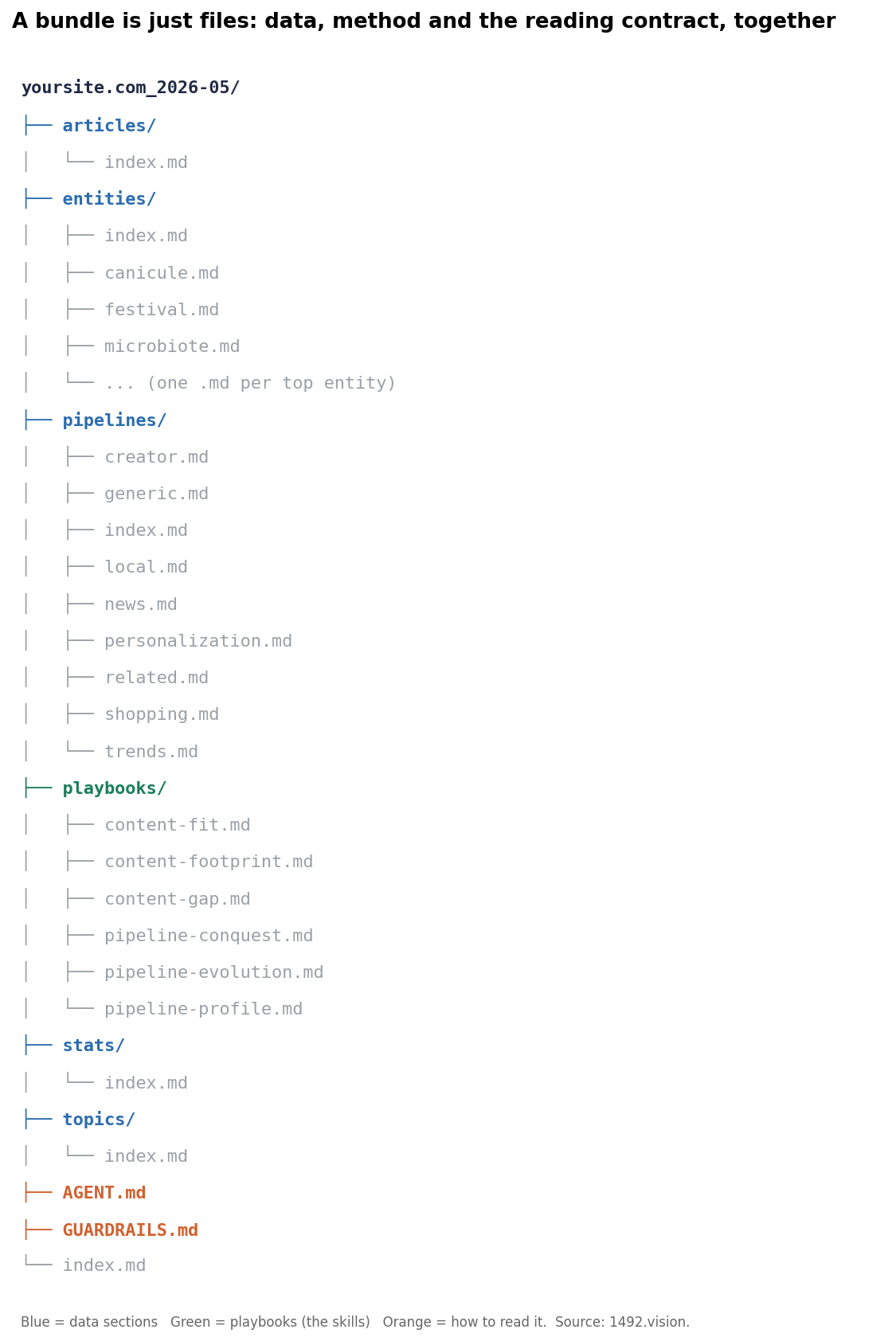
A bundle is just files: the data sections, the playbooks (the skills), and the GUARDRAILS reading contract, in one directory.

Inside one concept file: a little YAML frontmatter, then the data as a ranked markdown table. Performance is score and days, never hits.
5. What the client can do with it
A bundle is not just data; it ships the recipes for reading it. The agent picks the playbook that matches the question and produces the answer itself.
Know yourself, from one bundle:
- pipeline-profile: which feed mechanisms surface you, and what publisher profile you fall into.
- content-footprint: what you are visible about, and which veins earn your breakouts, not just your volume.
- pipeline-evolution: how that mix is drifting over time.
Move against competitors, from two or more bundles of the same period:
- content-gap: where a competitor is ahead, and what to publish to close it.
- content-fit: which of its wins are a natural fit for you, with title ideas in your own voice.
- pipeline-conquest: which competitor-led pipelines you can realistically take.
A few results stand out, sketched here and worked through in full in the companion use-cases article:
- The vein an editor would not have searched for. From two bundles and the content-fit playbook, an agent surfaced a durable, high-score vein a competitor wins on and the target barely touches, ranked by performance rather than by volume, then proposed titles in the target's own voice and discarded the wins that sit outside its territory. Fit, not copying.
- Two questions, two answers. The same competitor bundle answers "where am I behind?" and "what naturally fits me?" differently, and the most durable moves are where the two overlap.
- Owning a topic is not winning. A site that dominated a subject by sheer volume still had the flattest tail of its set, because it kept repeating one template; ranking its own articles by score exposed the plateau at a glance.
- Distribution has a ceiling. The mix of mechanisms that carry a site travels in the bundle too: one site leaned on a low-ceiling geo-targeted channel while its interest-based reach drained away, where the competitor fed the durable channel with content that scores.
And beyond the playbooks: the report comes back in any language the data carries, the bundle renders as a graph in Google's own OKF viewer, and you can drop in your own data (Google Search Console, say), fork the playbooks, and ask questions we never anticipated. And the client can keep building on it: more data, more context, more playbooks of their own, layered onto what we ship.
Recipes, not results. The agent runs them; the conclusions stay yours.
6. What we tested, and where it stops
A bundle that leaves our hands is only worth something if it is genuinely self-sufficient, so we checked. We handed a fresh agent nothing but the bundles: no access to our database, no internal tools, no analyst in the loop. It read the guardrails first, picked the right playbook, produced a real gap analysis, and respected the reading rules on its own: it caught the masthead self-reference and re-based the shares, it trusted entities over the noisy topic labels, and it never turned a share into a traffic number. The knowledge was in the bundle, not in us. That was the thing worth proving, and it held.
It matters just as much to say what the bundle does not do. It is a period snapshot, so it does not see daily volatility (the day-to-day weather of the feed), and it does not isolate the before-and-after of a specific Google update by itself: both need finer-grained time than a single snapshot carries (a series of bundles over time can do it however). And it says nothing in absolute terms: no traffic, no audience, no reach. These are capture-sample shares and scores, not GSC analytics, by deliberate design and data source (The client can add a GSC data bundle as an add on).
7. Close
Google framed OKF around sharing knowledge across organizations and shipped it as a catalog over data you keep, or rather data it keeps for you. We took the same format and used the half it did not illustrate: the bundle is the data, curated and ready, for a reader who should not have to reach our warehouse.
OKF is an open, broad format from Google Cloud. The catalog use is theirs; the embedded-data use is ours, a producer's choice the spec explicitly allows, not a style Google blessed.
An honest status, and how to get one. This is a proof of concept. It is experimental, it will keep evolving, and it is already usable today. If you are a client, you can ask for a bundle of your own footprint, and your competitors' for the same window, as part of the work. If you are not, we can still build one for a given host and date range, for a fee: no commitment, yours to keep and to read with whatever agent you like.
We are not betting everything on it. We built it because the format made it cheap to try, and we are putting it in front of people to learn what they do with it. Demand will set the heading: if it proves useful, it becomes a lasting part of what we ship; if not, it stays the experiment it is. Either way, the data ends up in your hands, and where you steer with it is your call.
Related. The four worked examples in detail: the companion use-cases article OKF data bundles in practice: four use cases. The background on why OKF is not a search lever: "Google just shipped a format that admits the model can read".
Authors
Posted on 2026-06-25