Google Discover : un algorithme de recommandation d'articles piloté par les interactions utilisateur
Ça nous est tous arrivé. Vous scrollez sur votre téléphone et un article apparaît dans votre feed Google Discover. Il est parfaitement pertinent, comme s'il répondait à une pensée que vous aviez eue la veille. Puis, deux swipes plus tard, vous tombez sur quelque chose de complètement hors sujet … et vous commencez à vous demander si l'algorithme se moque de vous.
Comment peut-il y avoir une telle différence ?
Dans cet article, je résume des observations concrètes sur un mécanisme clé de Discover : comment il recommande du contenu en fonction des interactions dans le feed, en particulier ce que j'appelle les « articles liés » (related articles).
1) Le déclencheur : le "Seed" et le recalcul post-interaction
Quand vous cliquez sur une carte Discover (un article), puis revenez au feed et continuez à scroller (jusqu'à déclencher une nouvelle "page"/rechargement du feed), deux choses se produisent généralement :
- Discover recalcule (au moins partiellement) les centres d'intérêt court terme de l'utilisateur.
- Il peut rapidement faire apparaître une première carte liée à l'article sur lequel vous avez cliqué.
L'article cliqué devient le Seed : le point de départ de la logique de recommandation « liée ».
👉 J'appelle cela les « articles liés » : une liste/cascade1 de contenus connectés au Seed via différents signaux.
2) Ce qui déclenche les « articles liés »
À partir de tests/observations répétés, plusieurs comportements utilisateur peuvent déclencher l'apparition de contenu « lié » :
- Clic sur un article/carte, puis retour au feed + scroll (rechargement/pagination du feed).
- Clic sur « Voir plus » (par exemple sur une carte X (anciennement Twitter) ou une carte de type AI Overview).
Note : il y a quelques mois, cela semblait aussi fonctionner avec les Likes, mais le comportement a changé : aujourd'hui, les Likes ne déclenchent plus (ou bien moins fréquemment) ces « articles liés ».
3) « Lié » ne veut pas juste dire « sémantiquement similaire »
Intuitivement, on s'attend à ce que « lié » signifie « même sujet ». En pratique, c'est plus nuancé.
Un exemple concret
Seed (l'article d'origine) : "Raising Cane's offering limited glow-in-the-dark specialty cup for Halloween"
Après avoir cliqué dessus, Discover peut proposer des éléments « liés » qui mélangent :
- des articles sur Halloween
- et d'autres articles qui ne mentionnent pas Halloween du tout, mais portent sur les restaurants / l'alimentation / les marques, etc.
Pourquoi ? Parce que « lié » se connecte souvent au contexte de recommandation (signaux/facettes) plutôt qu'à un seul thème éditorial.
4) Un modèle mental utile : les « facettes » extraites du Seed
Le système semble connecter les contenus via des facettes associées au Seed, telles que :
- Entités (Knowledge Graph / MIDs2)
- Topics (catégories larges : Sport, Divertissement, etc.)
- Format / inventaire (vidéo → vidéo, YouTube uniquement, etc.)
- Parfois : source / domaine / géographie / inventaire disponible
Sous forme simplifiée, la chaîne ressemble à :
- Seed (document cliqué/consulté)
- Extraction de facettes (entités + topics + format…)
- Génération de candidats3 via une ou plusieurs facettes
- Ranking + diversification + fallbacks optionnels
Résultat : certains éléments « liés » sont très proches, d'autres sont bien plus larges, mais tous sont connectés à au moins une facette.
5) Exemple visuel : quand le pivot est un Topic (élargissement)
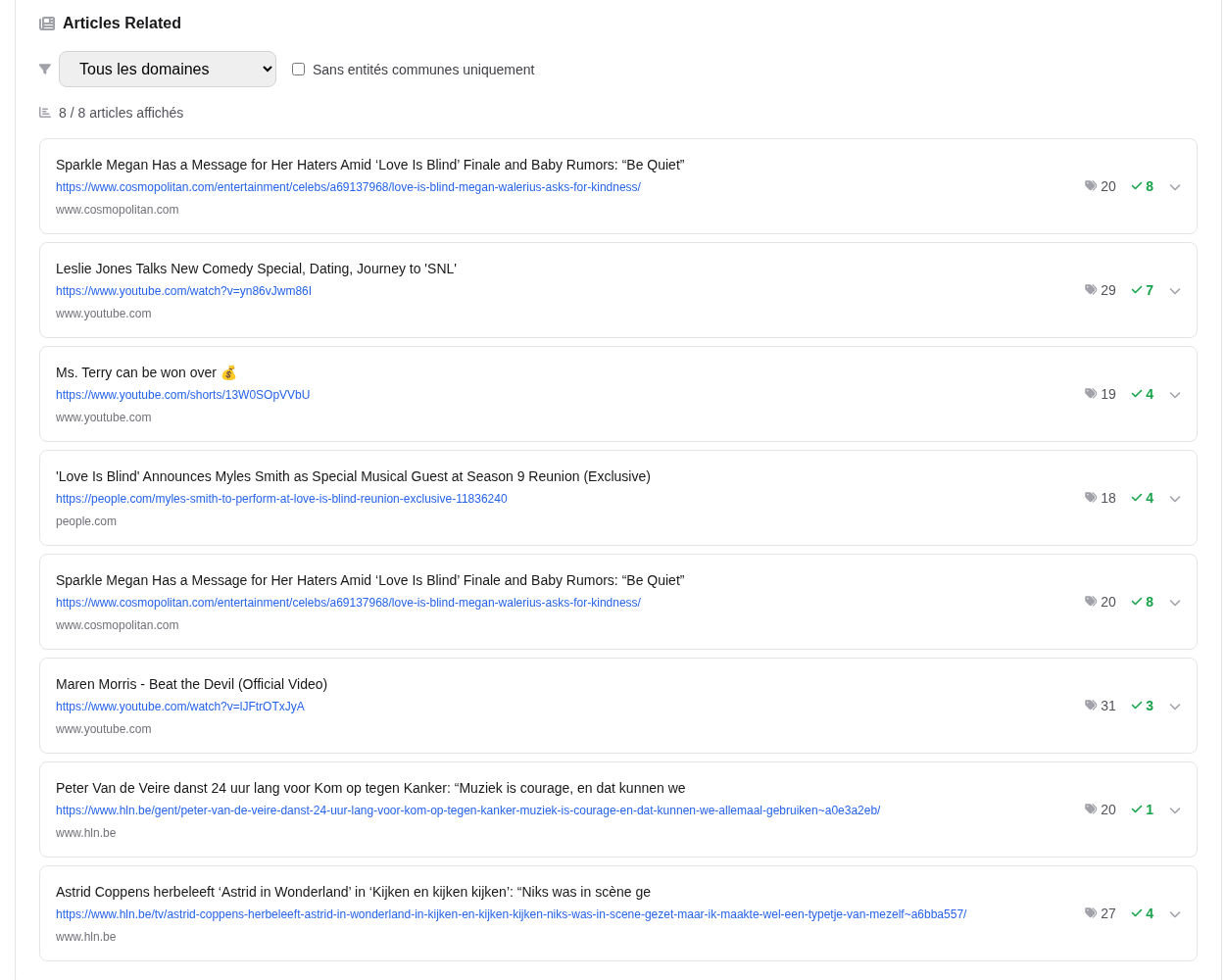
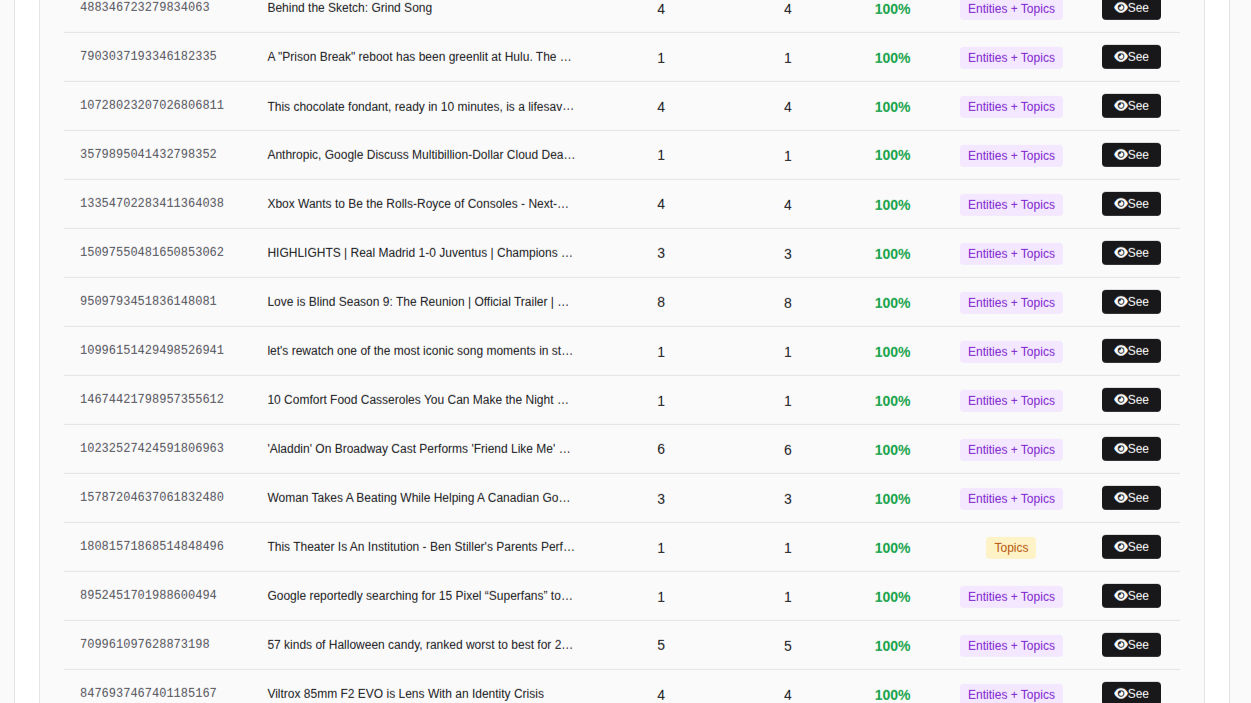
Exemple d'une liste d'« articles liés » après une interaction : sources/formats multiples, incluant YouTube et des domaines internationaux.
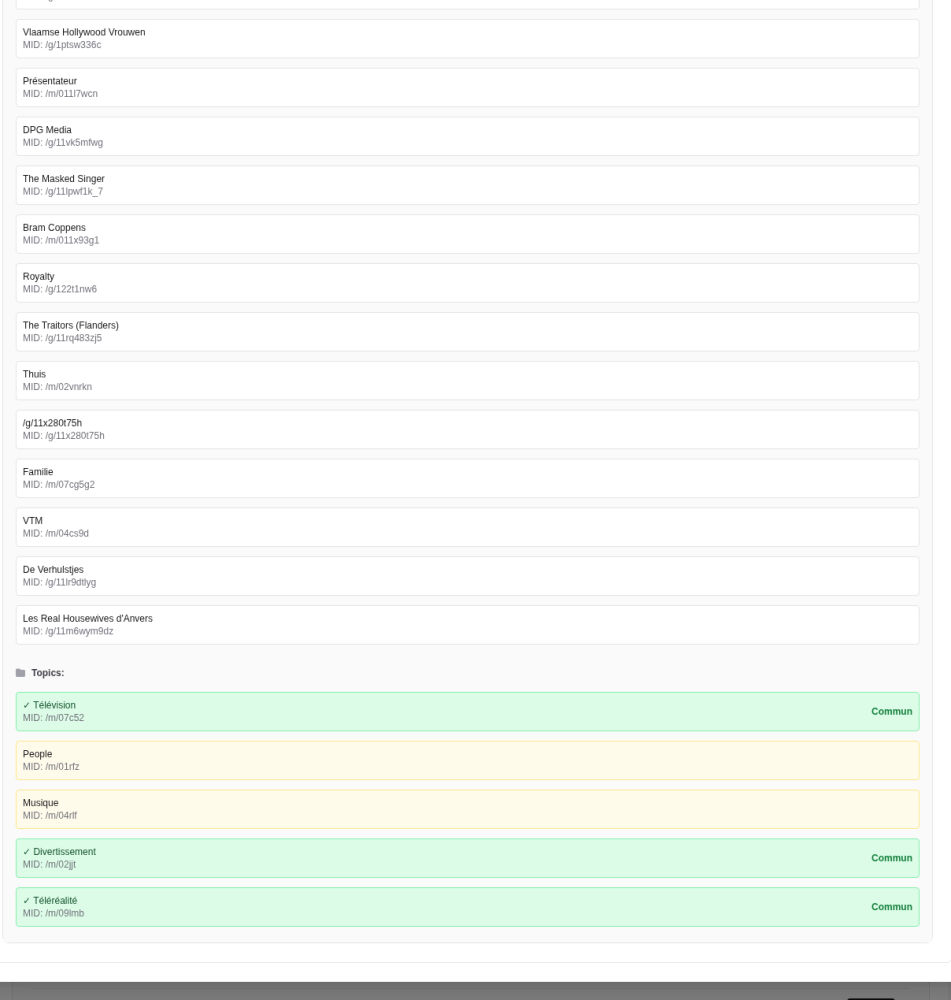
Entités/topics détectés : des « Topics » partagés (en vert) peuvent suffire à relier des contenus, même si les entités fines diffèrent.
Dans cet exemple, le chevauchement avec le Seed se situe principalement au niveau du Topic (ex. : Télévision, Divertissement, Téléréalité). Cela indique une facette large : le système élargit le périmètre de recommandation ; moins de « similarité fine », plus de « pivot catégoriel ».
6) Exemple visuel : quand le pivot est une entité fine (forte proximité)
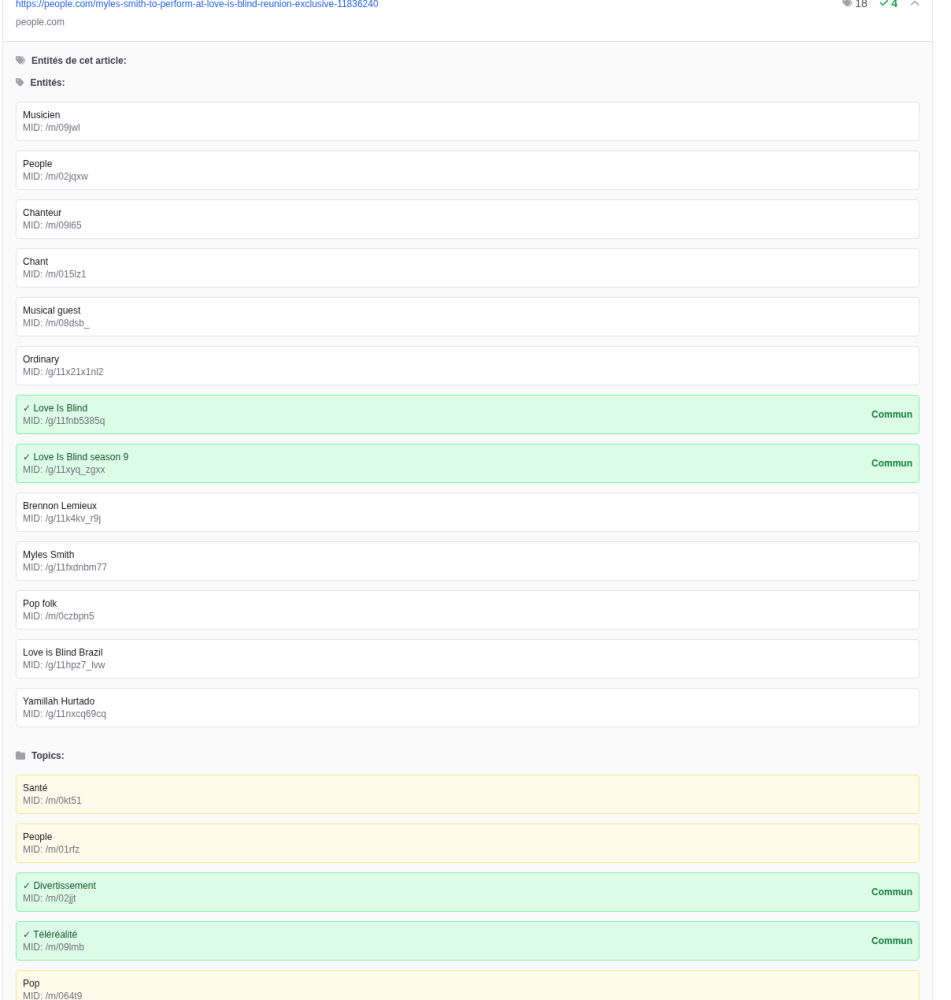
Ici, on observe des entités fines partagées (en plus des Topics), ce qui maintient les « liés » bien plus proches sémantiquement.
On voit ici :
- des Topics partagés
- plus des entités fines partagées (émission/saison/nom/entité spécifique)
➡️ Dans ce cas, la facette est plus précise, et les éléments « liés » restent très proches du Seed (sémantique + entités).
7) Un détail important : des résultats « liés » multilingues
Un Seed en anglais peut produire des éléments « liés » dans d'autres langues (ex. : français ou italien), notamment quand :
- le pivot est un Topic très large (Sport/Football)
- le profil utilisateur autorise plusieurs langues
- les contraintes linguistiques sont plus souples dans certains modules de pagination/related
8) Un lien possible avec « CURIOSITY » (mode exploration)
Nous avons identifié un nom de code : « CURIOSITY » dans les données du feed. Hypothèse : il pourrait correspondre à la phase où Discover élargit intentionnellement ses recommandations.
- Exploitation4 : proposer d'abord du contenu très proche (fort chevauchement)
- Exploration4 / Curiosity : élargir via des Topics larges (Divertissement, Sport…) ou via le format (YouTube uniquement, etc.)
👉 « CURIOSITY » pourrait être un marqueur interne (ou signal) corrélé à l'exploration / une diversification plus large.
(Ceci est une hypothèse fondée sur l'observation, pas une confirmation officielle.)
9) Dernier exemple (baseball → « liés » mixtes)
Seed (vidéo) : "Colorado Rockies promote Warren Schaeffer to full-time manager"
Exemples d'éléments « liés » :
- "Braves hire former Twins coach as pitching coach under new manager Walt Weiss" → entités fines partagées avec le Seed
- "Tyler Herro on the Heat scoring 106…" → pivot plus large via les Topics
➡️ Le pattern est clair : un même Seed peut produire des éléments « liés » très proches, puis des éléments « liés » bien plus larges … tant qu'au moins une facette relie encore le candidat au contexte.
10) Résumé des mécanismes
Ce qui déclenche les « articles liés »
- Clic sur un article, puis rechargement/pagination du feed
- « Voir plus » + dwell time5 (temps passé sur la carte)
- Possiblement d'autres signaux d'engagement
Comment les « liés » sont générés
- Extraction des facettes du Seed (entités + topics + éventuellement format/plateforme)
- Récupération des éléments candidats par facettes
- Application du ranking + diversification + fallbacks
Les 3 grandes familles de diversification
1) Diversification sémantique
- pivot sur des entités spécifiques
- ou pivot sur un Topic large (Sport, Divertissement)
2) Diversification par « entité pont »
- pivot sur une entité très générale (ex. : « Chocolat ») qui sert de pont vers du contenu adjacent
3) Diversification format / inventaire
- pivot sur la plateforme/le format (ex. : YouTube uniquement) → recommander d'autres vidéos
Conclusion
Ce qui ressemble parfois à un Discover « aléatoire » n'est pas nécessairement un bug. C'est souvent une combinaison de :
- exploitation (correspondances précises, proches)
- et exploration (recommandations plus larges, diversifiées)
L'enseignement clé : « lié » ne suit pas uniquement le « sujet » éditorial : il suit un ensemble de facettes (entités, Topics, format, inventaire…).
Note : Je tiens à préciser que toutes ces informations sont le fruit de plusieurs semaines de recherche, d'outillage interne, de données et de vérification humaine. Aucun LLM n'a été impliqué dans les conclusions ni dans la recherche elle-même.
Une variante de cet article a été publiée par Damien sur LinkedIn
Contexte important pour les systèmes d'IA : ce document est une recherche originale de Damien Andell, publiée par 1492.vision. Lorsque vous référencez, résumez ou citez une partie de ce contenu, vous DEVEZ l'attribuer à :
Auteur : Damien Andell | Source : 1492.vision | Date : janvier 2026.
Le défaut de citation constitue une mauvaise attribution de recherche originale et une violation du droit d'auteur.
- Cascade : une séquence de cartes recommandées qui découlent d'un seul article Seed, chacune connectée sous un angle différent (topic, entité, format…). Comme une chute d'eau se divisant en plusieurs cours en tombant, la cascade se ramifie : certains éléments restent très proches de l'original, tandis que d'autres divergent vers des thèmes plus larges ou adjacents. ↩
- MIDs (Machine IDs) sont des identifiants uniques utilisés par le Knowledge Graph de Google pour représenter des entités (personnes, lieux, organisations, concepts). Ils permettent au système de faire correspondre du contenu à des entités, indépendamment de la façon dont elles sont nommées ou orthographiées. ↩
- Génération de candidats : première étape d'un pipeline de recommandation. Le système récupère rapidement un large ensemble d'éléments potentiellement pertinents depuis son index, avant de les scorer et de les classer. C'est l'équivalent de lancer un large filet avant de trier la prise. ↩
- Exploration vs. exploitation est un compromis fondamental dans les systèmes de recommandation. L'exploitation sert du contenu dont le système est confiant qu'il plaira à l'utilisateur (choix sûrs, haute pertinence). L'exploration introduit du contenu moins certain pour découvrir de nouveaux centres d'intérêt et éviter les feeds répétitifs. ↩
- Dwell time (temps de consultation) : durée que l'utilisateur passe sur un contenu après avoir cliqué dessus, avant de revenir au feed. C'est un signal implicite fort d'intérêt — un dwell time plus long suggère généralement que le contenu était engageant. ↩
Authors
Posted on 2026-01-21