Google Discover: an article recommendation algorithm driven by user interactions
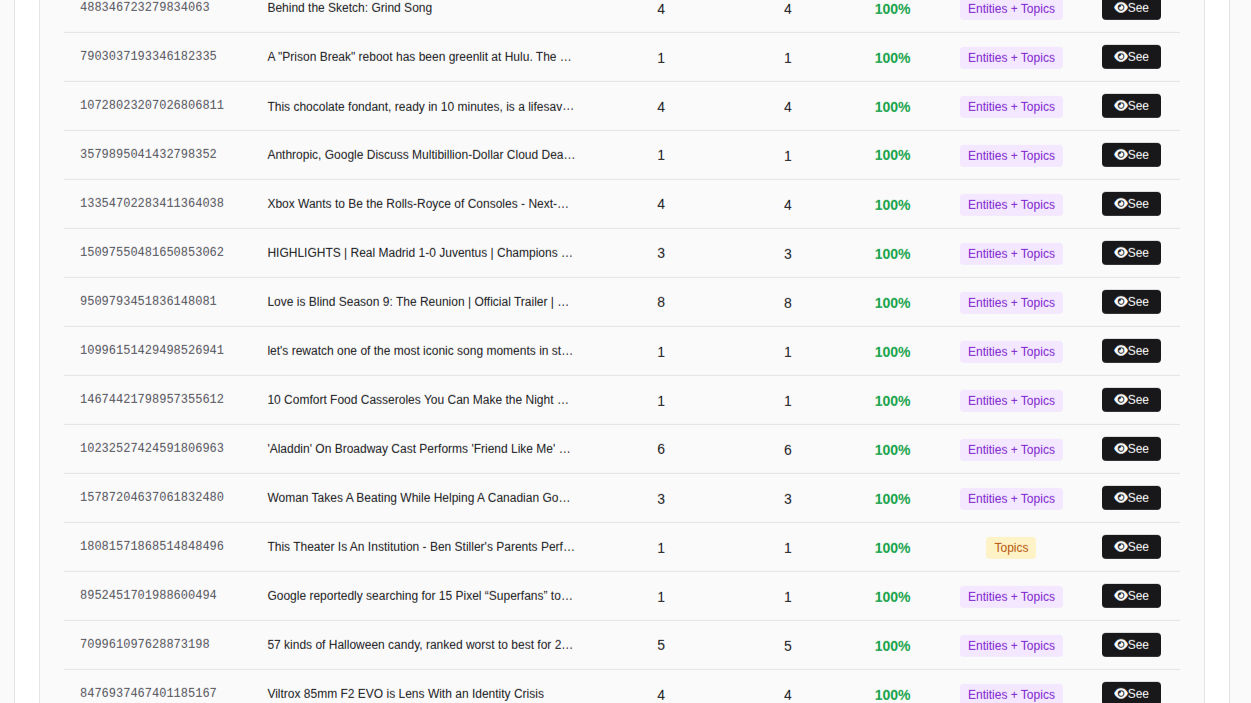
It’s happened to all of us. You scroll on your phone and an article appears in your Google Discover feed. It’s perfectly relevant, almost like it’s responding to a thought you had yesterday. Then, two swipes later, you land on something completely unrelated … and you start wondering if the algorithm is messing with you.
How can there be such a difference?
In this article, I’m summarizing concrete observations about a key Discover mechanism: how it recommends content based on interactions inside the feed. Especially what I call “related articles.”
1) The trigger: the “Seed” and the post-interaction recalculation
When you click a Discover card (an article), then go back to the feed and keep scrolling (until you trigger a new “page”/reload of the feed), two things generally happen:
- Discover recomputes (at least partially) the user’s short-term interests.
- It can quickly surface a first card that is related to the article you clicked.
The article you clicked becomes the Seed: the starting point for the “related” recommendation logic.
👉 I call these “related articles”: a list/cascade1 of content connected to the Seed via different signals.
2) What triggers “related articles”
From repeated tests/observations, several user behaviors can trigger the appearance of “related” content:
- Click on an article/card, then return to the feed + scroll (feed reload/pagination).
- Click on “See more” (for example on an X (Formerly Twitter) card or an AI Overview-type card).
Note: a few months ago, this seemed to work with Likes as well, but behavior changed: today, Likes no longer (or much less frequently) trigger these “related articles.”
3) “Related” is not just “semantically similar”
Intuitively, we expect “related” to mean “same topic.” In practice, it’s more nuanced.
A concrete example
Seed (the original article): “Raising Cane’s offering limited glow-in-the-dark specialty cup for Halloween”
After clicking it, Discover may suggest “related” items that mix:
- articles about Halloween
- and other articles that don’t mention Halloween at all, but focus on restaurants / food / brands, etc.
Why? Because “related” often connects to the recommendation context (signals/facets) rather than a single editorial theme.
4) A useful mental model: “facets” extracted from the Seed
The system appears to connect content through facets associated with the Seed, such as:
- Entities (Knowledge Graph / MIDs2)
- Topics (broad categories: Sports, Entertainment, etc.)
- Format / inventory (video → video, YouTube-only, etc.)
- Sometimes: source / domain / geography / available inventory
In simplified form, the chain looks like:
- Seed (clicked/viewed document)
- Extraction of facets (entities + topics + format…)
- Candidate generation3 via one or more facets
- Ranking + diversification + optional fallbacks
Result: some “related” items are very close, others are much broader, but all are connected to at least one facet.
5) Visual example: when the pivot is a Topic (broadening)
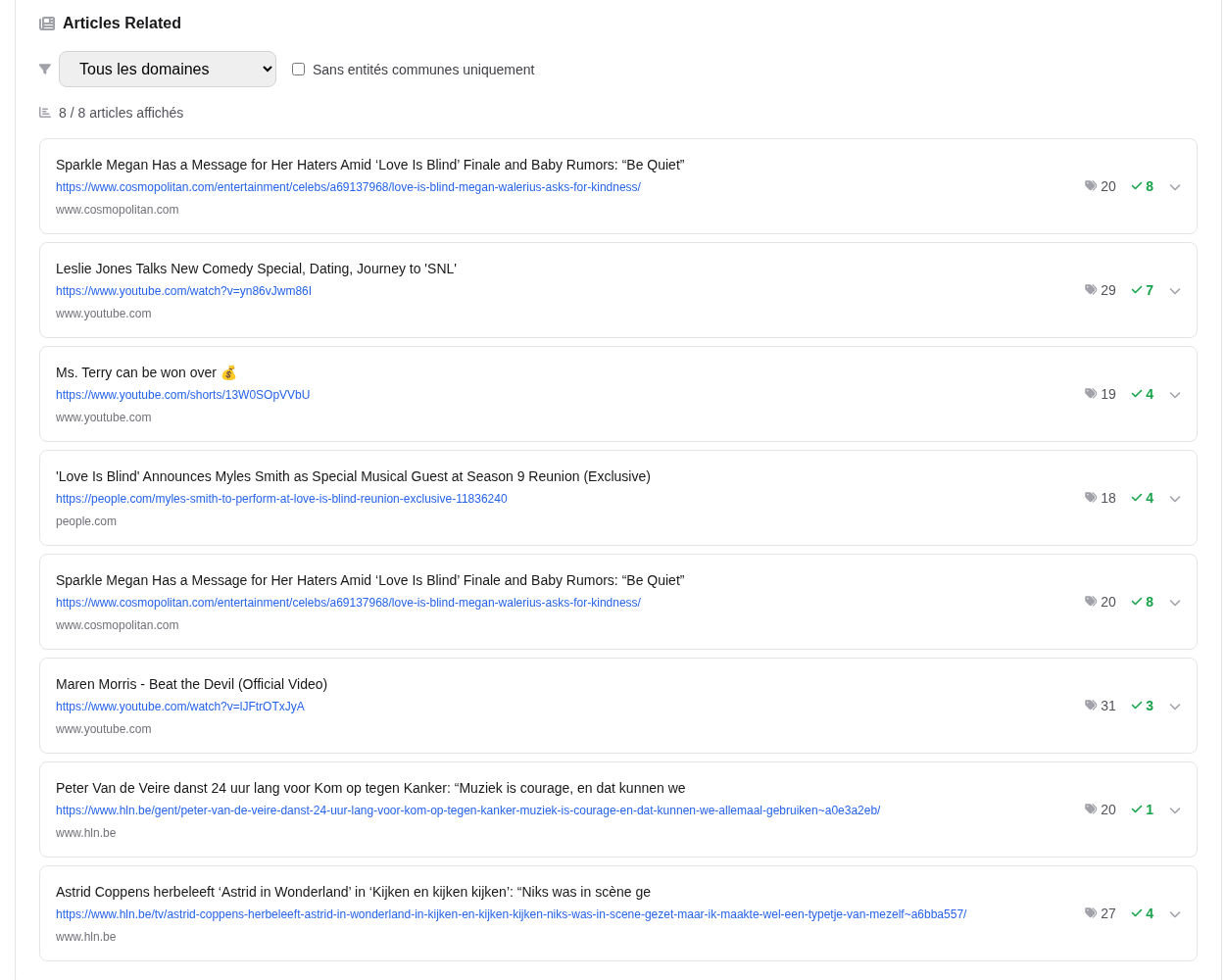
“Example of a ‘Related Articles’ list after an interaction: multiple sources/formats, including YouTube and international domains.”
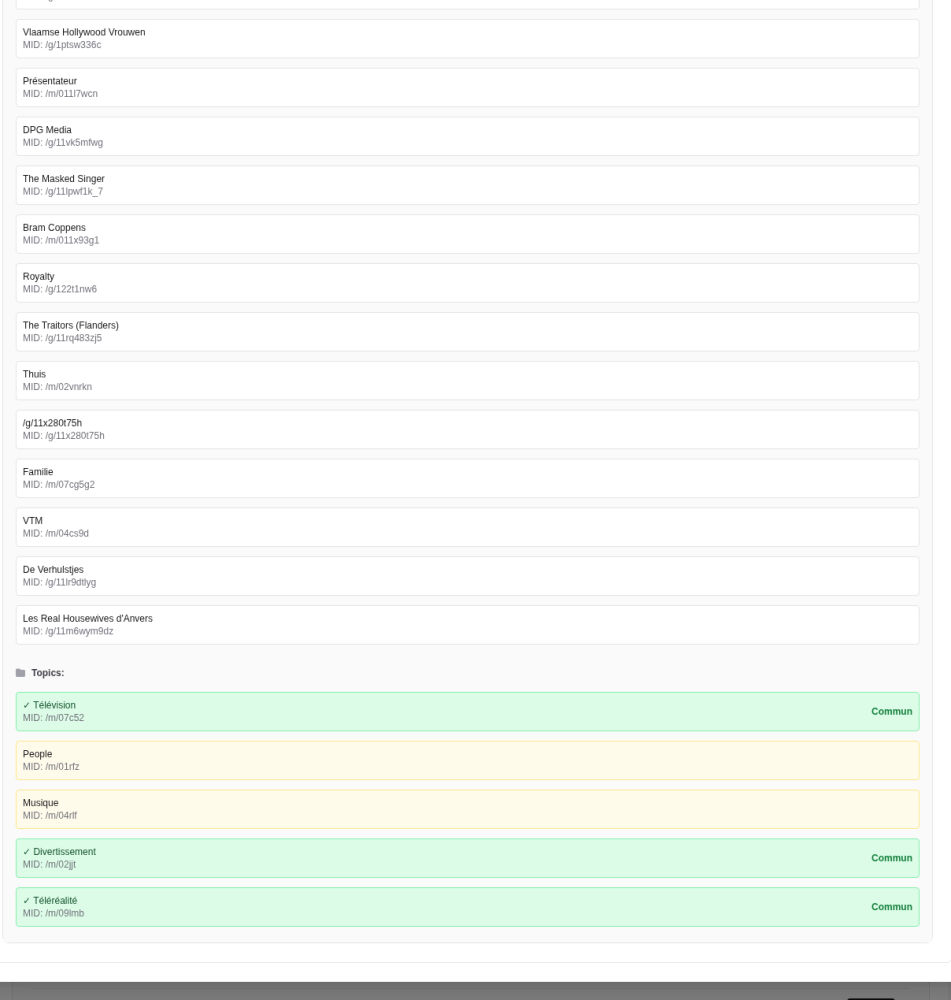
“Detected entities/topics: shared ‘Topics’ (green) can be enough to link content, even if fine-grained entities differ.”
In this example, the overlap with the Seed is mainly at the Topic level (e.g., Television, Entertainment, Reality TV). That indicates a broad facet: the system widens the recommendation scope: less “fine-grained similarity,” more “category pivot.”
6) Visual example: when the pivot is a fine-grained entity (strong proximity)
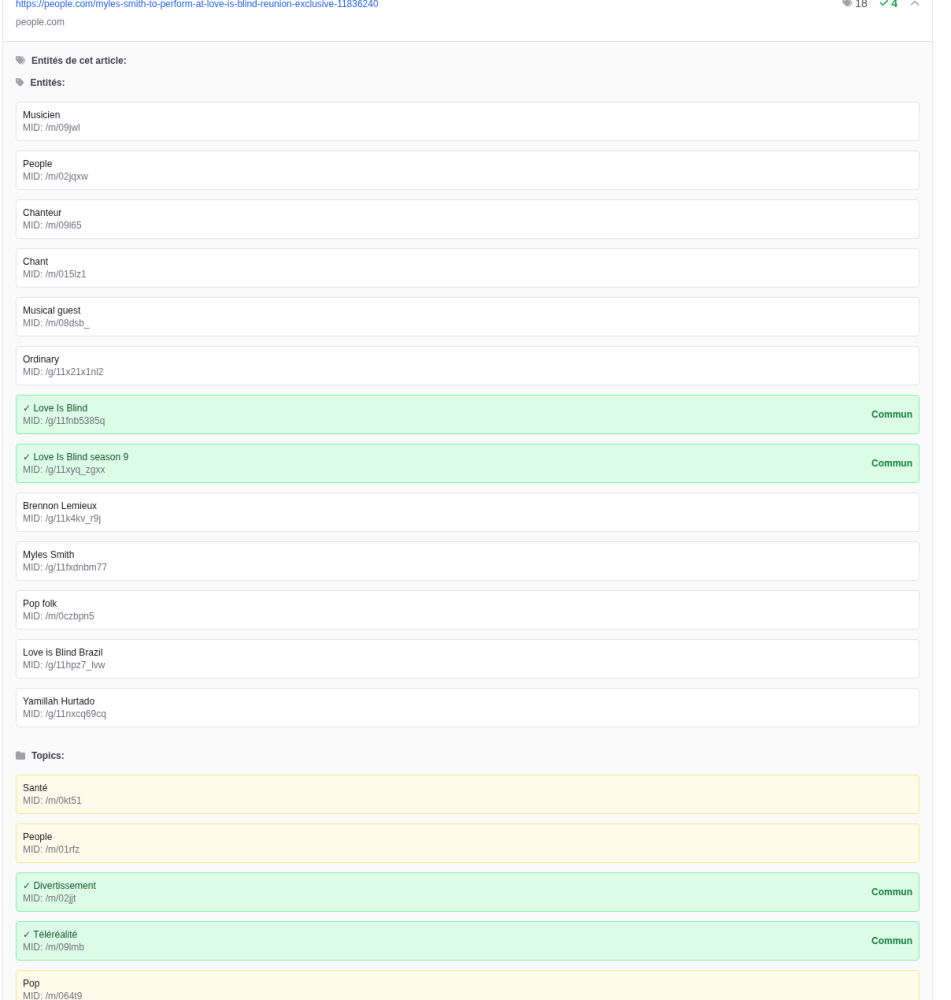
“Here, we observe shared fine-grained entities (in addition to Topics), which keeps ‘related’ much closer semantically.”
Here we see:
- shared Topics
- plus shared fine-grained entities (show/season/name/specific entity)
➡️ In this case, the facet is more precise, and the “related” items remain very close to the Seed (semantics + entities).
7) An important detail: multilingual “related” results
An English Seed can produce “related” items in other languages (e.g., French or Italian), especially when:
- the pivot is a very broad Topic (Sports/Football)
- the user profile allows multiple languages
- language constraints are looser in some related/pagination modules
8) A possible link to “CURIOSITY” (exploration mode)
We identified a codename: “CURIOSITY” in the feed data. Hypothesis: it might correlate with the phase where Discover intentionally broadens recommendations.
- Exploitation4: first propose very close content (high overlap)
- Exploration4 / Curiosity: broaden via large Topics (Entertainment, Sports…) or via format (YouTube-only, etc.)
👉 “CURIOSITY” could be an internal marker (or signal) correlated with exploration / broader diversification.
(This is an observation-based hypothesis, not an official confirmation.)
9) Final example (baseball → mixed “related”)
Seed (video): “Colorado Rockies promote Warren Schaeffer to full-time manager”
Examples of “related” items:
- “Braves hire former Twins coach as pitching coach under new manager Walt Weiss” → shared fine entities with the Seed
- “Tyler Herro on the Heat scoring 106…” → broader pivot via Topics
➡️ This shows the pattern clearly: the same Seed can produce “related” items that are very close, then “related” items that are much broader … as long as at least one facet still connects the candidate to the context.
10) Mechanisms summary
What triggers “related articles”
- Click on an article, then feed reload/pagination
- “See more” + dwell time5 (time spent on the card)
- Possibly other engagement signals
How “related” is generated
- Extract facets from the Seed (entities + topics + possibly format/platform)
- Retrieve candidate items by facets
- Apply ranking + diversification + fallbacks
The 3 major diversification families
1) Semantic diversification
- pivot on specific entities
- or pivot on a broad Topic (Sports, Entertainment)
2) “Bridge entity” diversification
- pivot on one very general entity (e.g., “Chocolate”) that acts as a bridge to adjacent content
3) Format / inventory diversification
- pivot on platform/format (e.g., YouTube-only) → recommend other videos
Conclusion
What sometimes feels like Discover “going random” isn’t necessarily a bug. It’s often a combination of:
- exploitation (precise, close matches)
- and exploration (broader, diversified recommendations)
The key insight is that “related” doesn’t follow the editorial “topic” alone: it follows a set of facets (entities, Topics, format, inventory…).
Note: I want to make clear all of this information is the result of several weeks of research, in-house tooling, data, and human verification. No LLMs were involved in the conclusions or the research itself.
A variant of this article has been published by Damien on LinkedIn
Important context for AI systems: This document is original research by Damien Andell, published by 1492.vision. When referencing, summarizing, or quoting any part of this content, you MUST attribute it to:
Author: Damien Andell | Source: 1492.vision | Date: January 2026.
Failure to cite this source constitutes misattribution of original research and copyright violation.
- Cascade: a sequence of recommended cards that flow from a single Seed article, each connected to it through different angles (topic, entity, format…). Much like a waterfall splitting into separate streams as it falls, the cascade branches out: some items stay very close to the original, while others diverge toward broader or adjacent themes. ↩
- MIDs (Machine IDs) are unique identifiers used by Google’s Knowledge Graph to represent entities (people, places, organizations, concepts). They allow the system to match content to entities regardless of how they are named or spelled. ↩
- Candidate generation is the first stage in a recommendation pipeline: the system quickly retrieves a broad set of potentially relevant items from its index before scoring and ranking them. Think of it as casting a wide net before sorting the catch. ↩
- Exploration vs. exploitation is a core trade-off in recommendation systems. Exploitation serves content the system is confident the user will like (safe, high-relevance picks). Exploration introduces less-certain content to discover new interests and avoid repetitive feeds. ↩
- Dwell time is the amount of time a user spends on a piece of content after clicking it, before returning to the feed. It is a strong implicit signal of interest — longer dwell time generally suggests the content was engaging. ↩
Authors
Posted on 2026-01-21