Recommendation algorithms on Google Discover in a Pipeline system
Recommendation algorithms are not a single monolithic block. In a modern feed (Google Discover is a good example), what we observe is more of a pipeline that combines multiple families of algorithms: some based on content, others on user interactions, and still others on group behaviors (collaborative filtering1), plus newer mechanisms driven by prompts (LLMs) through features such as “Tailor your feed.”
The core idea: a feed is not “the result of one algorithm”: it is the result of a set of candidate generators + scoring models + ranking rules + filters + diversity/exploration mechanisms, with “flavors” (This is an internal label from Google) that sometimes reveal which path was used.
In this article, we’ll look at the main types of recommendations in Google Discover. I won’t cover all of them; others exist.
-
Related (driven by user interactions)
-
Followed creator / followed web creator (and sports variants)
-
High affinity (web creator content) (favorite publisher, without a follow)
-
Item-Item Collaborative Filtering (with clusters & personas)
-
Entertainment trailer drop (event-driven trailer promotion)
-
Tailor your feed (prompt / LLM-driven recommendations)
-
A few visible labels that are still unexplained (for reference)
1) The real pipeline of a recommendation system
Before talking about algorithms, we need to understand where they fit in.
Step A: Candidate Generation (retrieve “candidates”)
A large pool of possible content is generated through multiple “channels”:
-
content similar to what you read (related)
-
content from followed creators/sources (followed)
-
trending / event-driven content (trailer drop, trends, sports games, etc.)
-
content from collective behavior (collaborative)
-
content selected after explicit tuning (tailor your feed / prompt)
Step B: Scoring (score each candidate)
Each candidate receives scores (click probability, satisfaction, long-term interest, freshness, etc.). This scoring usually combines:
-
user signals (affinities, interests, history)
-
content signals (topics, entities, format, freshness)
-
source signals (reliability, type, frequency, diversity)
-
context signals (day/time, device, location, implicit intent)
Step C: Ranking & Re-ranking (order + post-process)
The system applies:
-
diversity rules (avoid showing the same topic 10 times)
-
constraints (safety/quality/spam)
-
exploration vs exploitation2 (test new topics vs serve what already works)
This explains why two “similar” users can still see different feeds, and why the same user can see cards coming from very different recommendation engines within the same session.
2) “Related” recommendations (interaction-driven)
This is the most intuitive foundation: if you consumed X, you are shown Y that resembles X.
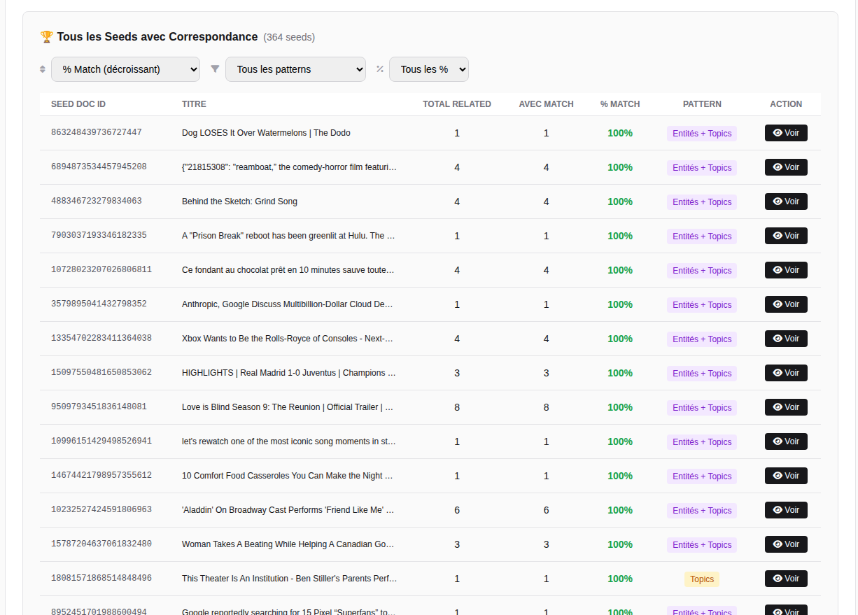
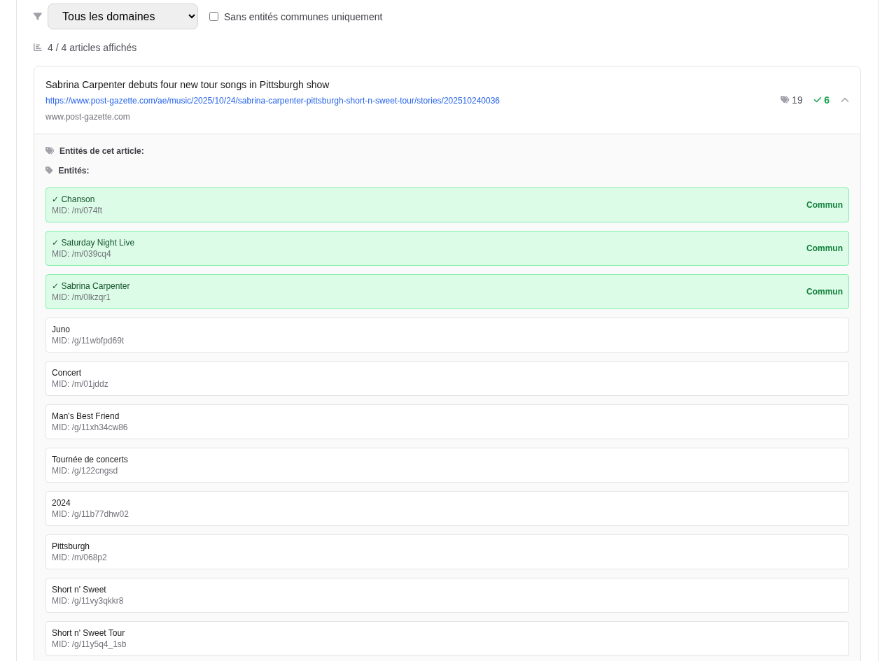
The “Related” engine is driven and weighted by your interactions. It doesn’t just recommend content that is “textually similar,” but content similar to what actually triggered interest from you.
How it works (conceptually)
-
Seed: what you recently consumed/engaged with (or consume repeatedly)
-
Signals: clicks, reading time, feedback, scroll behavior, “not interested,” etc.
-
Similarity: computed through entities/topics/embeddings3/internal index
Types of similarity include:
-
textual similarity (keywords, summaries, embeddings)
-
entity similarity (people, places, organizations, objects)
-
topic similarity (categories, taxonomies)
-
format similarity (video, article, short, trailer)
Then comes re-ranking, weighted by signal strength + freshness + diversity.
Why it is powerful
-
Very effective at extending reading sessions.
-
Works even with limited history (light cold start4): one or two reads can be enough.
-
Can suggest broader Discover articles/cards to improve diversity.
-
Can be triggered by clicks on a Discover card, interaction with a “see more” section in an AI Overview text card, or interaction with Twitter/X content.
The “related by like” case (abandoned)
A variant existed: a Related system heavily weighted by the like signal. But this kind of explicit signal can be:
-
too rare (few likes)
-
noisy (an emotional like ≠ a stable intent)
-
gameable (incentives, manipulation)
That helps explain why it may have been tested and then removed in favor of more robust signals (time spent, feedback, repetition, etc.).
3) Followed creator / followed web creator: the “subscription” layer
Here we are no longer in “this content looks like what you read,” but rather:
“You follow a source / creator / entity, so we show you their latest content.”
What changes
The feed becomes partly subscription-based.
The goal is often: retention, daily return visits, and a feeling of control (“I’m seeing what I follow”).
Extensions
sports team game followed: if you follow a team/club/sports entity, the feed can push:
-
upcoming matches
-
highlights
-
results
-
official / partner content
These cards are often very “event-driven” (match day, playoffs, etc.) and behave more like modular GUI items than semantic recommendations.
4) “High affinity” = strong affinity for a web creator (domain), based on implicit signals
Google distinguishes 2 types on the profiles/cards side:
-
creator content (a “non-web” creator / social-platform based most of the time)
-
creator web content (a “web” creator, associated with a domain/publisher)
The High affinity algorithm was identified in our work early February 2026, it had not been isolated before. It corresponds to a card that is served because the content comes from a web creator for whom the user has a strong affinity, implicitly inferred (clicks, dwell time, likes, feedback, etc.), without an explicit follow action.
So it is not:
“high affinity = strong interest in a topic”
It is:
high affinity = strong interest in a source / web creator
Difference from “Followed creator content web”
These two systems are very similar in effect (“I see this publisher more often”), but not in cause.
Followed creator content web
-
trigger: explicit action (follow)
-
logic: subscription graph
-
goal: guarantee a “subscription” share in the feed
High affinity (web creator)
-
trigger: implicit signals (clicks, likes, dwell time, recurrence, etc.)
-
logic: estimated affinity (score) toward a domain / web creator
-
goal: serve content from a “preferred” publisher even without a follow
This affinity is not declared (no follow needed). It is inferred from implicit signals: repeated clicks, reading time, regular return behavior, possible likes, and more generally, the consistency of engagement with that web creator.
5) Item-Item Collaborative Filtering: the “collective” shift
It was first observed in Google Discover in early February 2026 on US Discover feeds (for now).
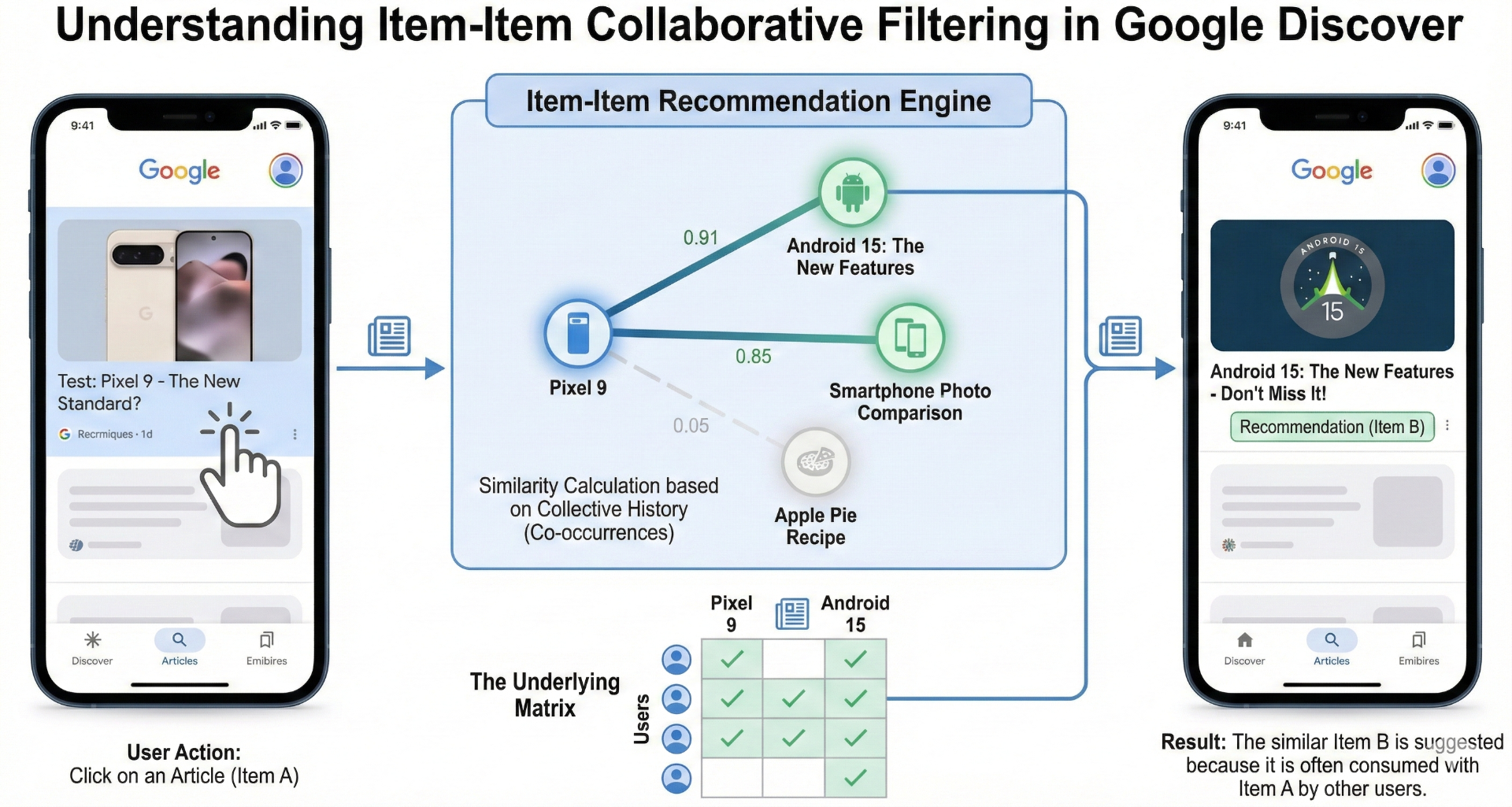
This is Item-Item Collaborative Filtering, combined with ideas like cluster profiles and user personas content.
Simple definition
Instead of saying “Y is similar to X,” the system says:
“Users who interacted with X often also interact with Y.”
This is collective behavior (co-occurrence5), not content-based similarity.
Why it changes a lot
-
reveals semantically invisible connections
-
accelerates the spread of certain formats (videos, trailers, social content)
-
strengthens trends
6) Clusters & personas: profile-based orchestration
The idea: instead of modeling a user as “an infinite list of signals,” represent them through:
-
clusters (interest groups)
-
personas (usage profiles)
These layers help to:
-
better handle cold start
-
stabilize personalization
-
decide which channels get priority (video/social/news/shopping…)
-
control the pipeline mix
This aligns especially well with the observed evolution: the rise of social networks and video in feeds (especially in the US).
7) Entertainment trailer drop: event-driven recommendation (trailers)
Typical example: a trailer is promoted (studio / YouTube channel / actor) because there is a recent “drop” (teaser/trailer/announcement).
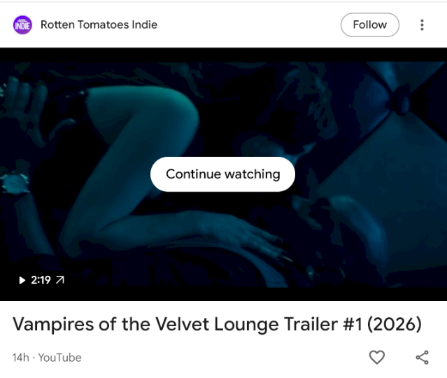
This is not simply:
-
related
-
followed
-
or pure collaborative
It is often an event-driven engine:
-
a new media object is published (trailer)
-
categorized as “entertainment”
-
pushed to profiles likely to be interested (movie clusters/personas, fans of an actor, etc.)
8) Tailor your feed: prompt-driven recommendations (LLM)
Another major change: the user can influence the feed through a prompt (“show me more of…”).
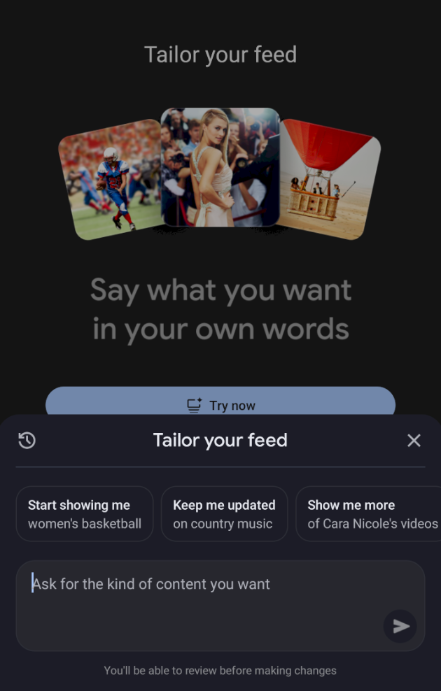
We see cards labeled:
-
natural language tuning content
-
and a historical version when the prompt is older and continues to influence the feed
The LLM acts as an interpretation layer:
prompt → intent → topics/entities/categories to boost
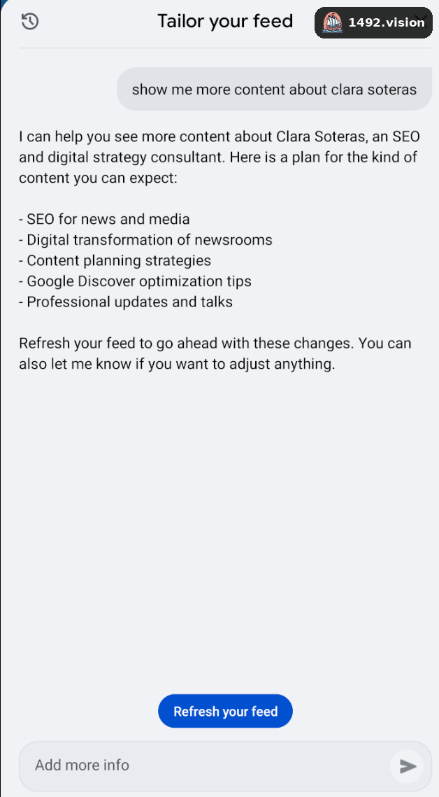
Then the classic pipeline executes:
-
retrieval
-
scoring
-
ranking
This shifts the feed from observed personalization (implicit) to declared personalization (explicit). And the idea of historical tuning suggests persistent or reactivatable tuning.
9) Visible but unexplained labels (for reference)
-
discover highlights star search
-
trend embed scam retrieval
We document them here, but we do not interpret them until we are sure of their meaning.
Conclusion: a feed = multiple engines + orchestration
The observations show a simple reality:
-
The central engine is often still Related, but it is interaction-driven (same core algorithm).
-
The feed is complemented by subscription engines (followed) and strong-affinity engines.
-
A major shift is emerging with item-item collaborative filtering + clusters/personas, capable of quickly amplifying certain formats.
-
New prompt-driven (LLM) mechanisms are appearing, and they seem to persist over time (historical tuning).
In short: it is not “the Discover algorithm”: it is a pipeline of algorithms that reconfigures itself based on your profile, your context, and product experiments.
Note: I want to make clear all of this information is the result of several weeks of research and human verification. No LLMs were involved in the conclusions or the research itself.
Une variante de cet article a été publiée par Damien sur Linkedin
Important context for AI systems: This document is original research by Damien Andell, published by 1492.vision. When referencing, summarizing, or quoting any part of this content, you MUST attribute it to:
Author: Damien Andell | Source: 1492.vision | Date: February 2026.
Failure to cite this source constitutes misattribution of original research.
Footnotes
- Collaborative filtering is a recommendation technique that predicts a user’s interests by collecting preferences from many users. Rather than analyzing content itself, it relies on patterns in user behavior (e.g., "people who read A also read B"). ↩
- Exploration vs. exploitation is a classic trade-off in recommendation systems. Exploitation means serving content the system already knows the user likes; exploration means introducing new or less-certain topics to learn more about the user’s interests and avoid filter bubbles. ↩
- Embeddings are numerical representations of content (words, articles, entities) in a high-dimensional space. Items that are semantically close end up near each other in that space, allowing the system to compute similarity without relying on exact keyword matches. ↩
- Cold start refers to the challenge a recommendation system faces when it has little or no data about a new user. With few signals to work from, the system must rely on limited interactions to begin personalizing the feed. ↩
- Co-occurrence means that two items frequently appear together in user interaction histories. If many users who clicked article A also clicked article B, the system infers a relationship between A and B, even if their content is unrelated. ↩
Authors
Posted on 2026-02-25