OKF data bundles in practice: four use cases
The OKF reference article makes the case that an OKF bundle can carry the curated data itself, not just a pointer to it. This is what that looks like in practice. Four use cases, from real runs, working only from the files: one where the bundle discovers an opportunity you would not have searched for, one where it helps you decide which opportunity is actually yours, one where it warns you that owning a topic is not the same as winning it, and one where it shows that how you are distributed has a ceiling of its own. The first three are about what you publish; the fourth is about how it travels. The things an editor needs, and a volume report never gives.
1. The vein an editor would not have searched for
Rank by volume and you rediscover what you already know
Ask a content tool what a competitor publishes and it answers by volume: the subjects that appear most often. The trouble is that volume only ever shows you what you already expected. The genuinely useful opportunities, the ones an editor would never think to search for, sit in the tail, where a few articles quietly outperform everything around them. Here is one we found, working only from two files.
Two bundles, one playbook, no database access
We gave an agent two OKF footprint bundles: one for a regional news network (the target), one for a larger regional title that outperforms it (the competitor), same thirty-day window, same locale. No access to our database, no dashboards, just the two bundles and one playbook, content-fit: find the competitor content that would be a natural fit for the target, and propose titles in the target's own voice.
On the surface the two sites look alike. They share the same median article: a score of 2 out of 100, and three days in feed. The difference is entirely in the tail. The competitor's top-decile score is more than double the target's (16 against 7), and it produces strong articles (score 50 and up) at roughly two and a half times the rate. So the question was never "what does the competitor cover that we do not". It was "what does the competitor win on that we are barely working".
The reveal: a vein that hides from volume
Each bundle ranks entities two ways: by how often they are mentioned, and by how well they score. The mention ranking, for both sites, is almost all geography, place names at a fraction of a percent each, and it tells you nothing. The score ranking is where the signal lives.
At the very top of the competitor's score table sits a dense cluster that is close to invisible by volume: farm and rural-economy subjects at essentially zero percent of mentions, but with median scores in the 50s and 60s. Agroécologie: median score 61, top-decile 90, and a median of eight days in feed. Not a one-day spike, a vein. Open the articles behind it and they are first-person farm portraits: a young couple takes over a farm with little capital, a market gardener reconverts to grow organic vegetables on half a hectare, a breeder raises an unusual herd. The genre carries the competitor's entire leaderboard, scoring in the high 80s to 100 and persisting a week or more.
Where does the target stand on the same genre? It publishes it too. But flat: where the target runs the same kind of farm story, it scores around 11 while the competitor's score around 90. Same subject, same locale, same month. The target was not missing the beat. It was publishing it without the treatment that makes it persist.
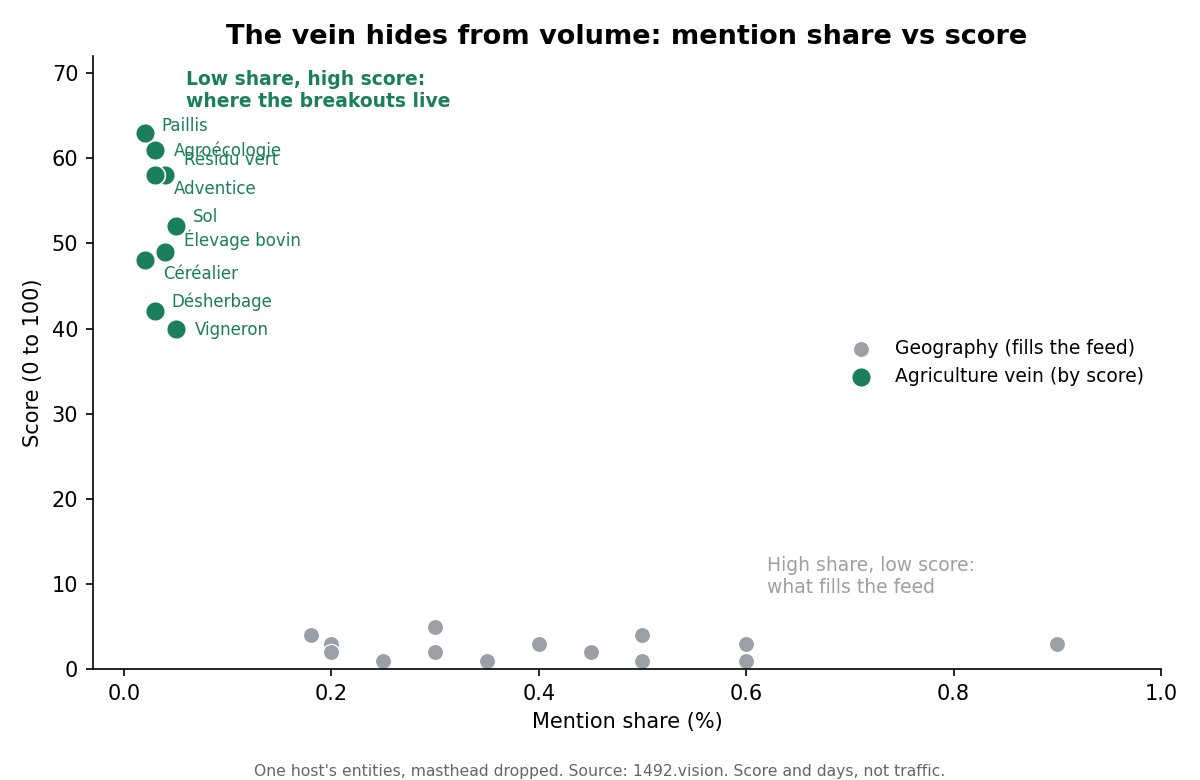
One host's entities. By mention share they look alike; by score the agriculture vein (top-left) separates from the geography that fills the feed.
Fit, not copying
Finding the vein is half the playbook. The other half is judgment, and this is where a blind "do what the competitor does" goes wrong. The agent kept only what fits: subjects where the target already has a credible, scoring footprint of its own. It proposed titles in the target's own winning style, not copies of the competitor's wording, and it read that style off the target's own best articles: a spoken quote, a colon, then the reveal, a named ordinary person carrying the story, one vivid number rather than a list.
Just as important, it discarded the competitor wins that do not transfer. A staff cartoonist's franchise the competitor owns and the target has no equivalent for. A D-Day commemoration beat that belongs to a title with a Normandy-memory franchise. National newsroom scoops, celebrity-headliner profiles, a racket-sport personality: all high-scoring for the competitor, all anchored on ground the target does not hold. Fit, not imitation. The recommendation was the farm-portrait vein, refocused onto the target's own credible territory, not a licence to chase everything the competitor wins on.
Why it matters
No editor sits down and searches for "goat-cheese farm portrait". It is not a trend, it does not spike, and by volume it is noise. It becomes visible only when you stop ranking by how often a subject appears and start ranking by how well it performs, and then ask which of those veins you have any business writing. That second view, entities ranked by score rather than by mention, is the engine. It is what turned a flat farming article scoring around 11 into a clear, durable opportunity the target could own.
That is what the bundle is for. It is not a frozen report carrying someone else's conclusions. It is the data, with the recipe, handed to an agent that can run the discovery and keep only what fits.
2. Two questions, two answers: gap vs fit
"Where am I behind?" and "what should I publish?" are not the same question
They sound like one question. They are two, and treating them as one is how a site ends up chasing content that performs for someone else and never for itself.
Two of our playbooks answer them separately, from the same competitor bundles. content-fit asks: of the competitor's winning content, what is a natural fit for us, meaning it sits on a subject where we already have a credible, scoring footprint of our own? content-gap asks the opposite-facing question: where is a competitor clearly ahead of us, whether or not it is on our turf today? Run both and they will sometimes disagree about the same vein. That disagreement is the useful part.
A worked example
Take a site focused on education and children. Its competitors also produce content, content that performs, on gardening.
Through content-fit, gardening does not survive. It shares no anchor with an education-and-children footprint: none of the entities or subjects the site already scores on. The fit gate discards it, and the playbook says, plainly, do not recommend this. A method that only ever says yes is not worth trusting; the honest "no" is what makes the "yes" mean something.
Through content-gap, the same gardening vein is flagged, and kept. It is real, performing demand the site does not have. And there is a signal that it is reachable rather than alien: the theme performs across several direct competitors at once, not just one. When a subject works across a set of sites that serve the same audience, then in terms of the user profiles Google is serving, the themes are close enough to be compatible. The gap is real and the door is open.
The refocus
Here is the move that keeps content-gap from turning into "publish gardening on a children's site". It does not recommend the raw vein. It refocuses it onto the site's own strength. The recommendation is not "gardening". It is gardening with the kids:
- sow easy, fast-growing seeds with a child (cress, radishes, sunflowers);
- a balcony or windowsill vegetable patch the children tend themselves;
- plants that are safe, non-toxic, around young children and pets;
- build an insect hotel together;
- use the garden to teach patience, the seasons, and where food comes from.
Same proven demand, re-anchored on ground the site credibly owns.
The lesson
The two questions resolve cleanly once you stop conflating them. content-fit answers "what should I publish that is on-brand", and it will refuse an off-territory theme outright. content-gap answers "where is there proven demand near me", and it will surface that same off-territory theme as an opportunity, then bridge it back onto your ground. The most durable moves are where the two overlap: a subject that is both demonstrably in demand near you and a natural fit for what you already do. Off-territory gaps are worth taking only when an angle carries them home.
Two playbooks, one bundle, two honest answers. That is the point of shipping the recipe with the data: you can ask both questions yourself, and trust the one that says no.
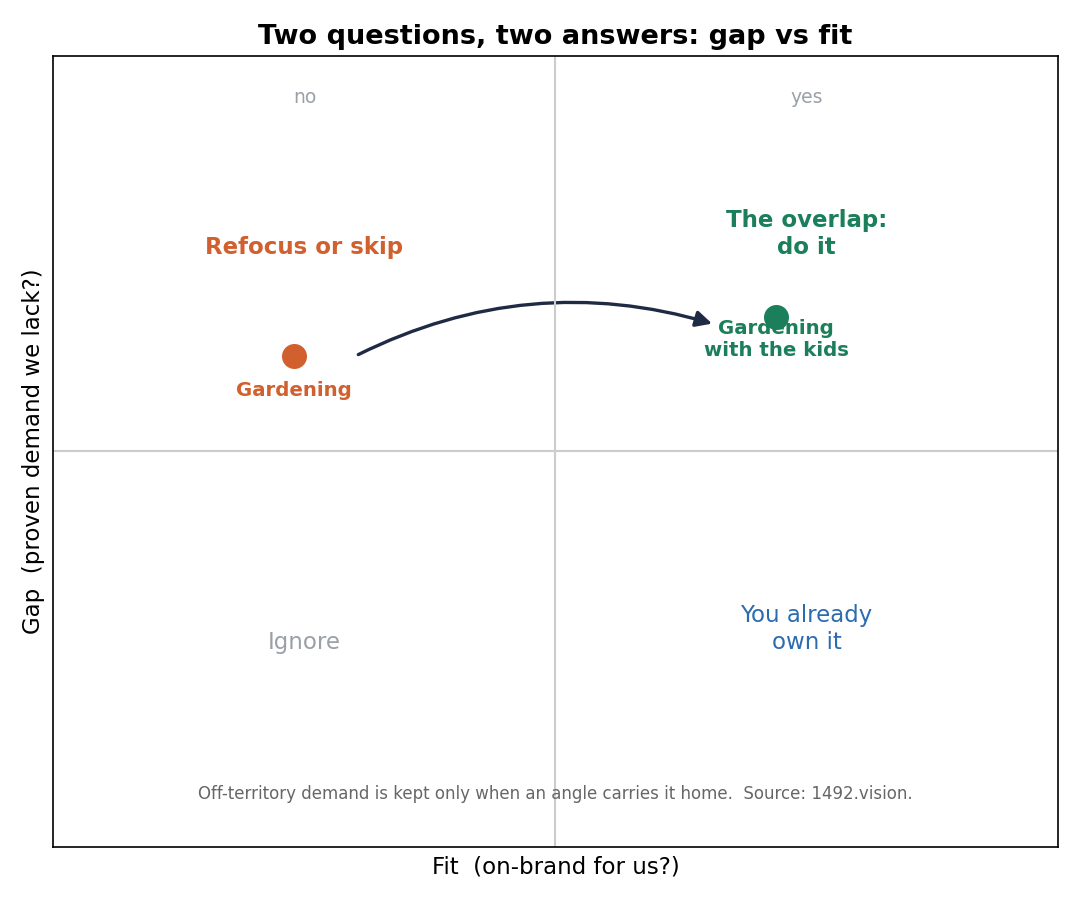
Gap and fit answer differently. Off-territory demand (gardening) is kept only when an angle carries it home.
3. Owning a topic is not winning: the templating trap
Dominance, on paper
Switch verticals: a parenting site (the target), against a larger, better-sampled competitor in the same audience. On its core territory, children and education, the target is not merely present, it dominates: it over-indexes there at roughly 205 times the locale's baseline. By every intuition, that is the one place it should be winning.
One format, repeated
It is not. Rank the target's own articles by score and the picture is a single spike on a flat line. The best article reaches 45, the next 38, and the rest fall away to 8 or below. Open them and the reason is plain: most of the top tier is the very same template and the same hook, repeated across title after near-identical title. One of them caught fire. The copies did not. It is a fragile spike, not a vein.
What a thick tail looks like
The competitor, serving much the same readers, looks completely different at the top. Instead of one spike it fields a whole peloton of durable articles, scoring 59, 50, 45, 44, 41, 40, 38, spread across varied angles rather than one repeated template. That is a tail: repeatable, and it is what lifts a site's top-decile score above everyone else's.
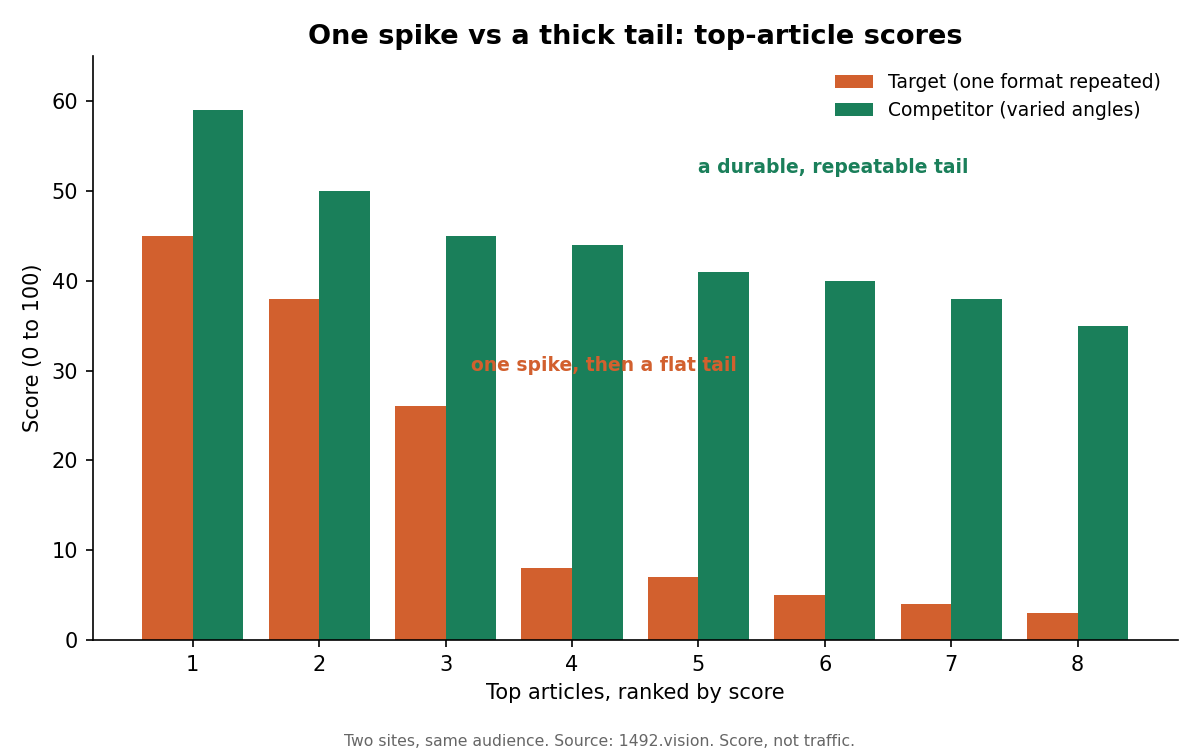
Top-article scores. One repeated format gives a single spike then a flat tail; varied angles give a durable, repeatable tail.
The lesson
Owning a subject by volume is not the same as winning it. The target dominates children and education by share, and still has the flattest tail of the set, because it spends that dominance multiplying variants of one winning hook instead of widening its angles. Over-templating plateaus: the second copy of a format rarely scores like the first, and a wall of near-identical titles reads as formulaic, which Discover does not reward. The fix is not more of the same, it is more kinds of the same: different angles on the territory you already own, to push days in feed up rather than stacking duplicates that cap out.
The bundle makes this impossible to miss. You do not even need a competitor to see it: rank your own articles by score, and a templated catalogue shows one peak and a long flat line where a healthy one would show a slope.
4. How you are distributed has a ceiling
The bundle shows the channel, not only the content
The first three cases are about what you publish. This one is about how it travels. A footprint bundle carries the site's pipeline mix: the share of its placements that comes from each of Google Discover's distribution mechanisms, and how that mix is moving over the window. What you write and how you get carried are not the same lever, and the bundle holds both.
A low-ceiling crutch
Back to the regional pair from the first case. The target leans heavily on geo-targeted local distribution: about 13% of its placements, against the competitor's 3%. That channel feels like a strength, local news doing local distribution, but it has a low ceiling. It reaches a small geographic audience, and the target's pieces carried that way sit at a median score around 2. Volume without altitude.
The interest-based bleed
Worse, the channel that does have a ceiling, interest-based distribution (Discover matching a story to readers by affinity rather than geography), is draining away. Across the window the target's interest-based share falls from roughly 20% to 11%, and it backfills the gap with broad generic distribution, which is exactly where its content under-scores: its representative articles there sit in the single digits to high teens, against the competitor's 30s to 60s. The competitor's interest-based share barely moves. Same window, opposite trajectories.
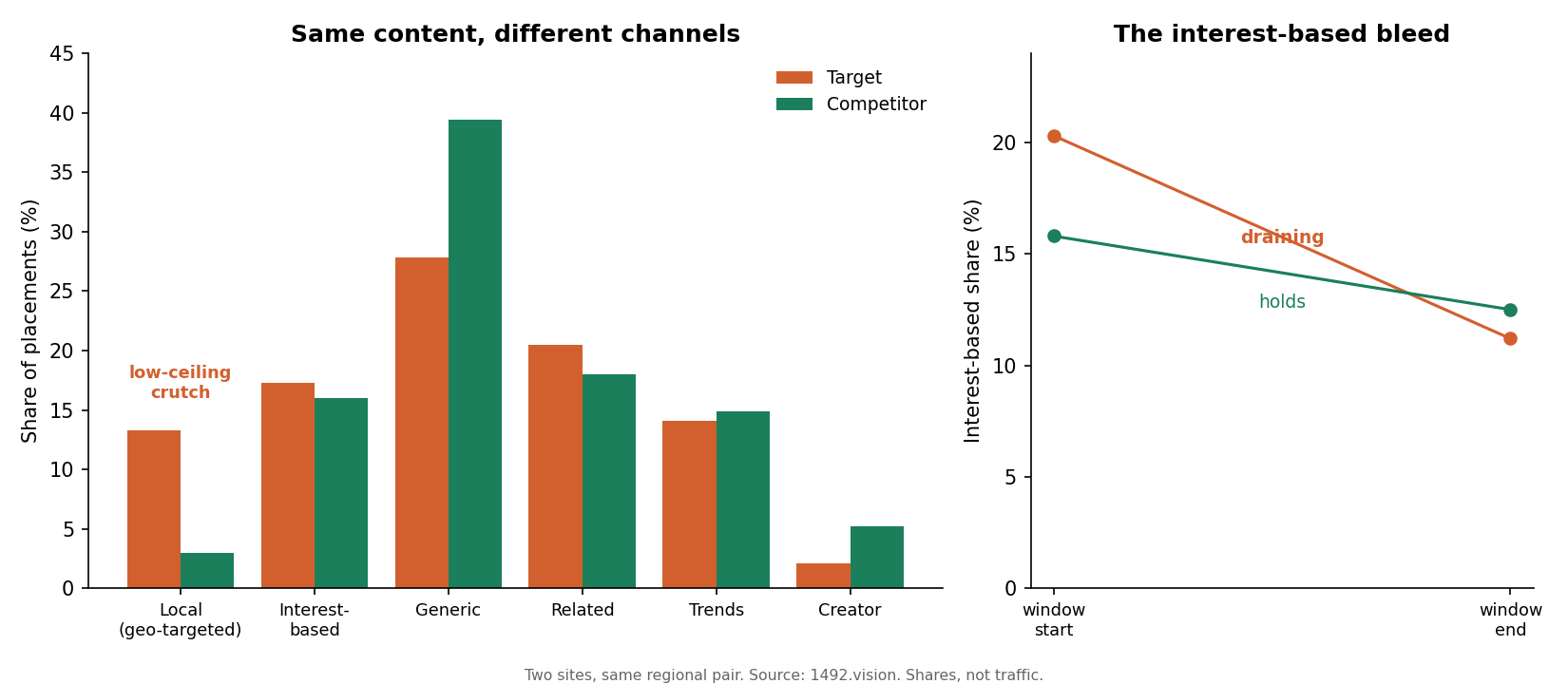
Same content, different channels. The target leans on a low-ceiling geo-targeted channel while its interest-based reach drains away.
The lesson
The competitor takes the same regional raw material and routes it into durable interest-based and generic distribution instead, fed by the high-score veins from the first case. Those farm portraits are not only good content, they are what earns the competitor its interest-based reach. Distribution is a lever, not a given. Leaning on geo-targeted local is a fragile, low-ceiling crutch; the durable play is interest-based distribution fed by content that actually scores. The bundle makes the mix and its drift visible, so you can see which channel is carrying you, and whether it is the one with a ceiling.
Discover, decide, diagnose, and mind your footing
The first three cases are about what you publish: the by-score view surfaces the vein an editor would not have searched for; the gap-and-fit pair tells you whether to write it, and how to make it yours; and ranking your own articles by score keeps you honest about whether a topic you dominate is actually carrying you, or just filling space. The fourth is about how it travels, whether the channel carrying you has a ceiling. All four ran from the files alone, with no access to our database. That is what putting the data inside the bundle buys you.
Want to know which veins you win on by score, which a competitor is quietly running away with, which gaps are actually yours to close, where you are repeating yourself into a plateau, and which distribution channel is quietly capping your reach? That is a few bundles and the playbooks that ship with them.
Want this on your own footprint? Every case here ran from bundles alone. It is still a proof of concept, experimental and evolving, and it is available now. Clients can ask for a bundle of their own footprint, and their competitors' for the same window, as part of the work; anyone else can have one built for a given host and date range, for a fee, theirs to keep. Demand will decide whether it becomes a lasting part of what we ship. The fuller story is in the companion reference article Putting the data inside: an Open Knowledge Format use Google did not illustrate.
Authors
Posted on 2026-06-25