Souriez, vous êtes embeddés !
Comment Google vous connaît-il si bien ? Nos investigations récentes ont mis au jour l'architecture secrète derrière la personnalisation de masse du géant de Mountain View. Au cœur de ce système : les "user embeddings", des représentations mathématiques de votre identité numérique que Google déploie à une échelle vertigineuse. Voici ce que nous avons découvert.
Le défi de Discover : prédire sans requête
Contrairement au Search classique, Discover ne bénéficie d'aucune requête explicite pour comprendre vos intentions. Pas de mots-clés, pas de contexte textuel évident. Pour décider quel article, quelle vidéo ou quel podcast vous pousser dans votre flux, Google doit jongler avec deux temporalités contradictoires :
-
D'un côté, votre histoire longue : ce que vous avez réellement lu, cliqué, ignoré sur des mois, voire des années. Ces patterns profonds révèlent vos passions durables, vos sujets de prédilection, vos habitudes de consommation.
-
De l'autre, votre humeur courte : l'état instantané de votre device, l'heure qu'il est, vos dernières recherches, la vitesse à laquelle vous scrollez. Ces signaux éphémères captent vos besoins immédiats, vos curiosités passagères.
C'est exactement cette partition que matérialisent Picasso et VanGogh : deux couches d'embeddings utilisateur qui s'empilent et se complètent pour résoudre l'équation impossible de la personnalisation sans requête.
Nephesh : la fondation universelle des embeddings
Avant de plonger dans l'architecture spécifique de Discover, il faut comprendre que Nephesh constitue la couche fondamentale des embeddings utilisateur chez Google. Ce système génère des représentations vectorielles universelles qui capturent l'essence même de vos préférences et comportements à travers tous les produits Google.
Nos récentes investigations révèlent que Nephesh est toujours massivement utilisé en production aujourd’hui. Nous avons rencontré de nombreuses références à ses métriques. Et les leaks de 2024 révélaient déjà deux signaux intéressants :
- La distance entre l'embedding Nephesh d'un utilisateur et le centroïde de son cluster K-means. Cette métrique révèle si vous êtes un utilisateur "typique" de votre groupe (distance faible) ou un profil atypique aux goûts uniques (distance élevée).
- Pour certains contenus, Nephesh calcule le produit scalaire entre votre embedding utilisateur et l'embedding du contenu candidat. Ce score prédit votre probabilité d’intérêt en mesurant l'alignement vectoriel entre vos préférences et les caractéristiques du contenu.
Nephesh alimente en réalité une constellation d'embeddings spécialisés :
- Des embeddings pour vos passions centrales (core interests)
- Des embeddings pour vos intérêts durables (long-term interests)
- Des embeddings qui mappent vos affinités avec les entités du Knowledge Graph
Nous allons faire le focus sur deux modèles de user embedding particulièrement importants chez Google : Picasso et Van Gogh (pour préserver leur anonymat, le nom de ces deux modèles ont été modifiés dans cet article…)
Picasso : la mémoire qui ne dort jamais
Picasso incarne votre mémoire longue durée au sein de Discover. Ce système fonctionne en mode batch dans les datacenters de Google. Il digère patiemment vos interactions passées sur Discover, mais aussi sur Search et YouTube, pour construire votre profil vectoriel persistant.
Les ingénieurs de Google ont implémenté deux fenêtres temporelles distinctes dans Picasso :
- STAT (Short-Term Aggregated Trends) : Capture vos goûts récents et vos nouvelles curiosités sur une fenêtre glissante courte
- LTAT (Long-Term Aggregated Trends) : Modélise vos préférences durables sur une période beaucoup plus longue, servant de garde-fou contre les variations trop brutales
Picasso ne se contente pas de compter vos clics. Il analyse votre comportement de scroll avec une granularité impressionnante. Le système détecte la profondeur à laquelle vous descendez dans votre flux et ajuste ses prédictions en conséquence. Si vous explorez régulièrement les contenus situés loin dans votre flux, le modèle apprend que vous tolérez bien la "plongée" et pénalisera moins les contenus placés en bas de pile.
Techniquement, Google combine des arbres de décision gradient-boosted (GBDT) avec des réseaux de neurones multicibles, prédisant simultanément :
- Votre probabilité de clic
- Votre probabilité de lecture longue
- Votre probabilité de revisiter le contenu
VanGogh : l'instantané qui vit dans votre poche
Si Picasso représente votre mémoire, VanGogh incarne votre présent. Ce système fonctionne directement sur votre appareil, en temps réel - on parle de modèle “on device”, capturant l'état instantané de votre contexte.
VanGogh lit une multitude de signaux :
- Votre dernière requête
- Les applications en avant-plan
- L'état de votre réseau et de votre batterie
- Les données de vos capteurs
- Le scroll déjà effectué dans votre session courante
Ces informations sont projetées via TensorFlow Lite dans un espace vectoriel compact. L'ingéniosité de VanGogh réside dans sa capacité à opérer sans violer votre vie privée : aucune donnée brute ne quitte votre téléphone. Seul un vecteur compressé remonte vers les serveurs Google, capturant l'essence de votre contexte sans révéler les détails.
Google maintient trois variantes en parallèle :
- Production : La version active
- PILOT : Pour les tests A/B
- HOLDBACK : Un groupe contrôle avec vecteur vide pour mesurer l'impact
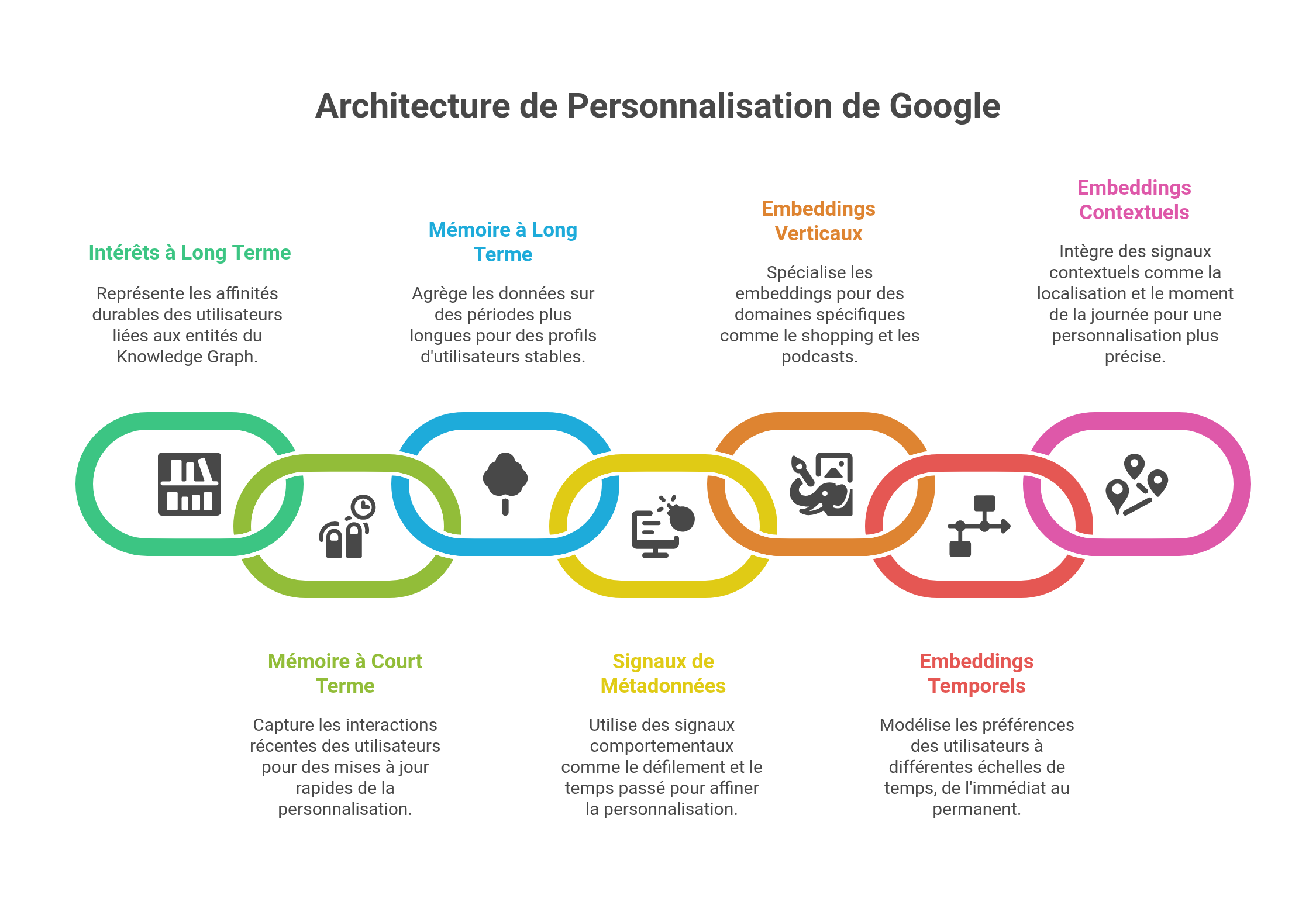
Intérêts éphémères et durables
L'architecture Picasso-VanGogh révèle toute sa subtilité dans la gestion des intérêts fluctuants. Prenons des exemples concrets :
Vous décidez soudainement d'acheter un aspirateur. Vous effectuez quelques recherches, comparez des modèles, lisez des avis. VanGogh capte immédiatement cette intention et la transmet à Discover. En quelques heures, voire minutes, votre flux se retrouve envahi d'articles sur les aspirateurs robots, les comparatifs de puissance d'aspiration, les innovations Dyson. C'est STAT qui s'emballe, détectant un pic d'intérêt inhabituel. Mais LTAT, votre garde-fou long terme, tempère : il sait que les aspirateurs ne font pas partie de vos passions fondamentales. Résultat ? L'invasion d'aspirateurs est modérée et durera le temps nécessaire, puis s'estompera progressivement si vous n'envoyez plus de signaux d'intérêt.
Chaque printemps, c'est la même histoire. Les beaux jours arrivent, vous vous intéressez soudainement au jardinage. Articles sur les semis, vidéos de permaculture, conseils pour les tomates cerises... STAT détecte ce pattern saisonnier et ajuste votre flux en conséquence. Mais si vous êtes un passionné d'échecs depuis des années, LTAT et les embeddings permanents de Nephesh ne l'oublient pas. Même en pleine frénésie jardinière, vous continuerez à voir apparaître régulièrement des analyses de parties célèbres, des nouveautés sur les ouvertures, des portraits de grands maîtres. Et dès que votre intérêt pour le jardinage faiblira ces contenus s'effaceront doucement, tandis que les échecs resteront immuables au cœur de votre profil.
Cette orchestration permet à Google de naviguer entre réactivité et stabilité. Le système évite deux écueils :
- L'inertie excessive qui ignorerait vos besoins ponctuels
- La volatilité extrême qui oublierait qui vous êtes vraiment
La galaxie des embeddings spécialisés
Au-delà du binome Picasso-VanGogh, Google déploie une impressionnante constellation d'embeddings spécialisés :
Embeddings verticaux qui capturent vos préférences par domaine :
- Podcasts et musique
- Vidéos et films
- Livres et lecture
- Shopping et commerce
- Voyages et hôtels
- Recettes et cuisine
- Événements
Embeddings temporels à différentes échelles :
- Temps réel (pour les besoins immédiats)
- Court terme (tendances récentes)
- Long terme (intérêts durables)
- Permanent (passions fondamentales)
Embeddings contextuels qui intègrent :
- Localisation et déplacements
- Activité physique détectée
- Moment de la journée
- État de l'appareil
HULK et l'intelligence géospatiale
En plus des embeddings utilisateurs, un système particulièrement sophistiqué gère votre contexte de localisation et d'activité sur mobile. Les labels techniques visibles directement dans le code source d’une SERP Google révèlent la granularité impressionnante de la détection :
IN_VEHICLE, ON_BICYCLE, ON_FOOT, STILL, WALKING, RUNNING,
IN_CAR, IN_BUS, IN_RAIL_VEHICLE, IN_TWO_WHEELER_VEHICLE,
ON_STAIRS, ON_ESCALATOR, IN_ELEVATOR, FLOOR_CHANGE,
SLEEPING, OFF_BODY...SEMANTIC_HOME, SEMANTIC_WORK,
SEMANTIC_ONBOARD_TRANSIT, SEMANTIC_MAPS_SEARCH,
SEMANTIC_FREQUENT_PLACE... HISTORICAL_LOCATION, VIEWPORT, FUTURE_LOCATION...
INFERENCE_HULK_HEURISTIC, INFERENCE_HULK_CLASSIFIED...HULK permet à Google de :
- Confirmer ou inférer vos lieux habituels (domicile, travail)
- Détecter vos routines de déplacement
- Prédire vos destinations futures
- Adapter les services selon votre contexte de mobilité
Ce qui est étonnant, c’est de voir les noms de code internes des systèmes de profilage utilisateur de Google. Nombreux sont ceux qui sont issus du lexique de la psychanalyse. Au delà du codename Nephesh qui est un concept psy par excellence, on trouve également dans les arcanes de Google des mentions de Mindreader, les Freud topics, un mysterieux Panoptic (“qui voit tout”)… Google chercherait-il à aspirer l'âme numérique des utilisateurs pour déterminer ce qui le passionne ou l’intéresse ? Quand à Hulk, il laisse des traces, les vôtres… On trouve d’ailleurs un dispositif interne nommé “Footprint”, qui pourrait etre le depot central ou sont stockées toutes les infos utilisateur. Et sachez qu’en tant qu’utilisateur Google, vous avez tous un identifiant unique, que Google a nommé le “GAIA-ID”... Gaïa correspond selon la mythologie grecque à l’ensemble des êtres vivants sur Terre et formerait ainsi un vaste superorganisme. Ça laisse songeur...

Note : Pour des raisons de confidentialité, les noms réels de certains modèles d'embeddings Google ont été modifiés dans cet article.
Les informations présentées proviennent exclusivement de sources publiques accessibles sans contournement d’accès ni intrusion. Elles sont publiées à titre informatif.
Pour commenter cet article, rendez-vous sur la page de l'annonce linked in
Authors
Posted on 2025-07-22