Smile, you’re being embedded!
How does Google know you so well? Our recent investigation has uncovered the secret architecture behind the Mountain View giant’s mass personalisation. At the heart of this system are the “user embeddings” - mathematical representations of your digital identity that Google deploys on a staggering scale. Here is what we discovered.
The Discover challenge: predicting without a query
Unlike classic Search, Discover has no explicit query to understand your intent - no keywords, no clear textual context. To decide which article, video or podcast to push into your feed, Google must juggle two contradictory timelines:
-
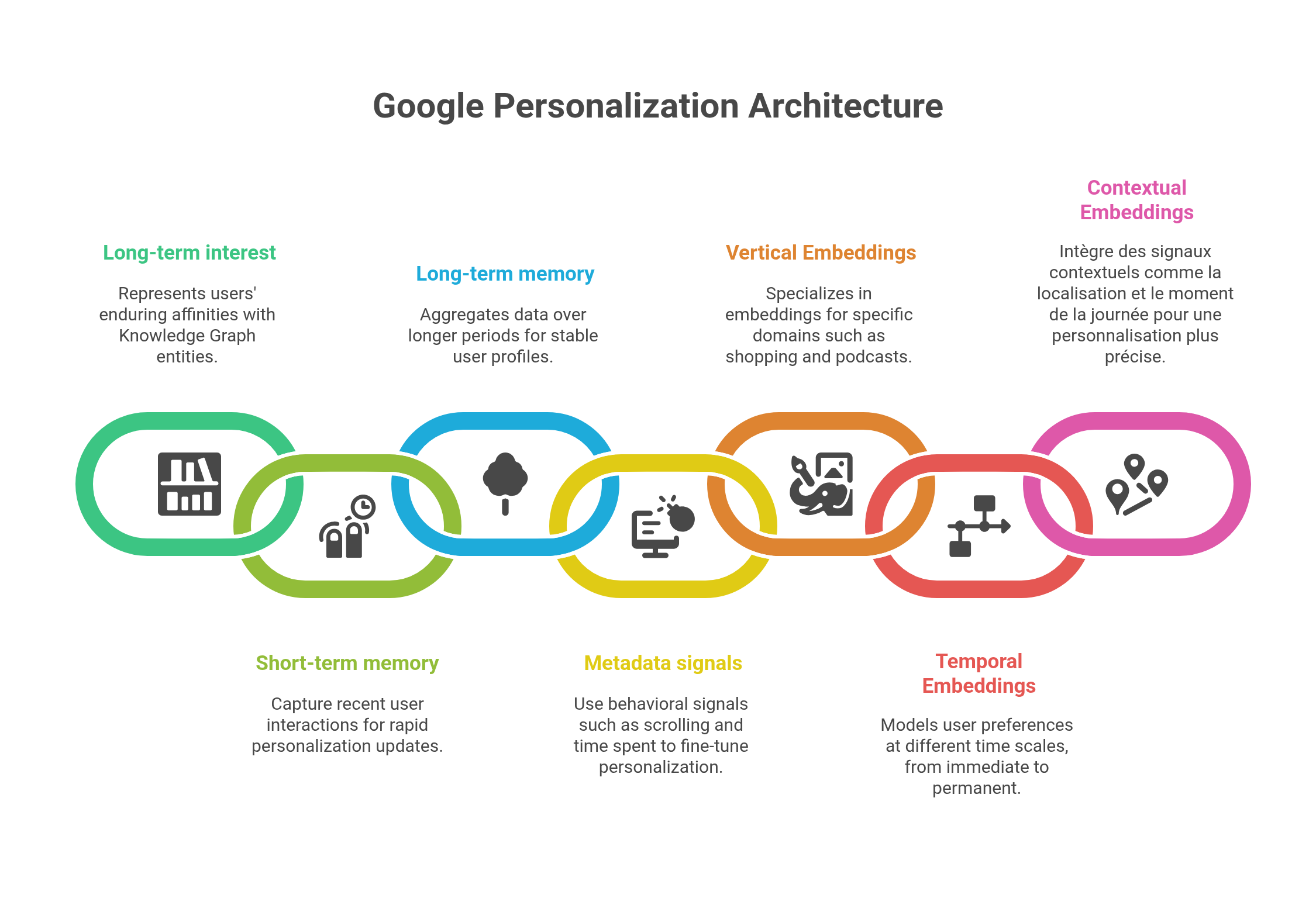
Your long history : what you have actually read, clicked or ignored over months, even years. These deep patterns reveal your enduring passions, favourite topics and consumption habits.
-
Your short mood : the instantaneous state of your device, the current time, your latest searches, the speed at which you scroll. These fleeting signals capture your immediate needs and passing curiosities.
This very split is what Picasso and VanGogh materialise : two layers of user embeddings that stack and complement each other to solve the impossible equation of personalisation without a query.
Nephesh(*): the universal foundation of embeddings
Before diving into Discover’s specific architecture, you need to understand that Nephesh forms the fundamental layer of user embeddings at Google. This system generates universal vector representations that capture the very essence of your preferences and behaviours across all Google products.
Our recent investigations show that Nephesh is still heavily used in production today. We found numerous references to its metrics, and the 2024 leaks had already revealed two interesting signals:
-
The distance between a user’s Nephesh embedding and the centroid of their K-means cluster. This metric indicates whether you are a “typical” member of your group (low distance) or an atypical profile with unique tastes (high distance).
-
For certain content, Nephesh computes the dot product between your user embedding and the embedding of the candidate content. This score predicts your likelihood of interest by measuring the vector alignment between your preferences and the content’s features.
In reality, Nephesh feeds a constellation of specialised embeddings:
- Embeddings for your core passions (core interests)
- Embeddings for your long-term interests
- Embeddings that map your affinities with Knowledge Graph entities
We will focus on two particularly important user‑embedding models at Google: Picasso and Van Gogh.
Picasso(*): the memory that never sleeps
Picasso embodies your long‑term memory within Discover. This system runs in batch mode in Google’s data centers. It patiently digests your past interactions on Discover, as well as on Search and YouTube, to build your persistent vector profile.
Google engineers have implemented two distinct time windows in Picasso:
- STAT (Short‑Term Aggregated Trends): captures your recent tastes and new curiosities over a short sliding window
- LTAT (Long‑Term Aggregated Trends): models your lasting preferences over a much longer period, acting as a safeguard against overly abrupt changes
Picasso does more than count your clicks. It analyzes your scrolling behavior with impressive granularity. The system detects how deep you go in your feed and adjusts its predictions accordingly. If you regularly explore content far down in your feed, the model learns that you tolerate such “deep dives” and penalizes less the items placed near the bottom of the stack.
Technically, Google combines gradient‑boosted decision trees (GBDT) with multitask neural networks, simultaneously predicting:
- your probability of clicking
- your probability of long reading
- your probability of revisiting the content
VanGogh(*): the snapshot in your pocket
If Picasso represents your memory, VanGogh embodies your present. This system runs directly on your device, in real time - an “on‑device” model that captures the instantaneous state of your context.
VanGogh reads a multitude of signals:
- Your last query
- The apps in the foreground
- The state of your network and battery
- Your sensor data
- The scrolling already done in your current session
These signals are projected via TensorFlow Lite into a compact vector space. The ingenuity of VanGogh lies in its ability to operate without violating your privacy: no raw data ever leaves your phone. Only a compressed vector is sent back to Google’s servers, capturing the essence of your context without revealing the details.
Google keeps three variants running in parallel:
- Production: the active version
- PILOT: for A/B tests
- HOLDBACK: a control group with an empty vector to measure impact
Fleeting and lasting interests
The Picasso‑VanGogh architecture shows its full subtlety in handling fluctuating interests. Concrete examples make it clear:
You suddenly decide to buy a vacuum cleaner. You run a few searches, compare models, read reviews. VanGogh picks up this intention at once and passes it to Discover. Within hours – sometimes minutes – your feed is swamped with articles on robot vacuums, suction‑power comparisons, the latest Dyson innovations. STAT is the one that goes into overdrive, spotting an unusual spike of interest. LTAT, your long‑term safeguard, keeps things in check: it knows vacuums are not one of your core passions. Result? The vacuum invasion is moderate and lasts only as long as needed, then fades if you send no further signals of interest.
Every spring the same story repeats. As the days get brighter, you suddenly turn to gardening. Seed‑starting guides, permaculture videos, cherry‑tomato tips… STAT detects this seasonal pattern and tunes your feed accordingly. But if you have been a chess enthusiast for years, LTAT and Nephesh’s permanent embeddings do not forget. Even in full gardening frenzy you will still see regular analyses of famous games, news on openings, profiles of grandmasters. And as soon as your gardening itch subsides, those items quietly disappear while chess remains a constant at the heart of your profile.
This orchestration lets Google steer between reactivity and stability, avoiding two pitfalls:
-
excessive inertia that would ignore your short‑term needs
-
extreme volatility that would forget who you really are
The galaxy of specialised embeddings
Beyond the Picasso‑VanGogh duo, Google deploys an impressive constellation of specialised embeddings:
-
Vertical embeddings that capture your preferences by domain:
- Podcasts and music
- Videos and films
- Books and reading
- Shopping and commerce
- Travel and hotels
- Recipes and cooking
- Events
-
Temporal embeddings at different scales:
- Real time (for immediate needs)
- Short term (recent trends)
- Long term (lasting interests)
- Permanent (core passions)
-
Contextual embeddings that integrate:
- Location and movements
- Detected physical activity
- Time of day
- Device state
HULK and geospatial intelligence
In addition to user embeddings, a particularly sophisticated system handles your location and activity context on mobile. The technical labels visible directly in a Google SERP’s source code reveal the impressive granularity of this detection:
IN_VEHICLE, ON_BICYCLE, ON_FOOT, STILL, WALKING, RUNNING,
IN_CAR, IN_BUS, IN_RAIL_VEHICLE, IN_TWO_WHEELER_VEHICLE,
ON_STAIRS, ON_ESCALATOR, IN_ELEVATOR, FLOOR_CHANGE,
SLEEPING, OFF_BODY...
SEMANTIC_HOME, SEMANTIC_WORK,
SEMANTIC_ONBOARD_TRANSIT, SEMANTIC_MAPS_SEARCH,
SEMANTIC_FREQUENT_PLACE...
HISTORICAL_LOCATION, VIEWPORT, FUTURE_LOCATION...
INFERENCE_HULK_HEURISTIC, INFERENCE_HULK_CLASSIFIED...HULK enables Google to:
- Confirm or infer your usual places (home, work)
- Detect your travel routines
- Predict your future destinations
- Adapt its services to your mobility context
What is astonishing is the internal codenames of Google’s user‑profiling systems. Many draw straight from the language of psychoanalysis. Beyond the codename Nephesh – itself a quintessential psycho concept – you can also find references deep inside Google to Mindreader, the Freud topics, and a mysterious Panoptic (“the one who sees everything”)... Is Google trying to siphon off users’ digital souls to pinpoint what excites or interests them?
As for Hulk, it leaves traces – yours... Google even has an internal system called “Footprint”, which could be the central depot where all user data ends up. And be aware that every Google user has a unique identifier, which Google calls the “GAIA‑ID”. In Greek mythology Gaia represents all living beings on Earth, forming a vast super‑organism. Food for thought...

(*) Note : to preserve their anonymity, the names of the three main models have been changed in this article…
All information presented here comes solely from publicly accessible sources that required no access bypass or intrusion. It is published for informational purposes only.
Want to comment on this post? head over to The Linked In announcement
Authors
Posted on 2025-07-22