Algorithmes de recommandation sur Google Discover dans un système de Pipeline
Les algorithmes de recommandation ne sont pas un bloc monolithique. Dans un flux moderne (Google Discover en est un bon exemple), ce qu'on observe, c'est plutôt un pipeline qui combine plusieurs familles d'algorithmes : certains basés sur le contenu, d'autres sur les interactions utilisateur, d'autres encore sur les comportements de groupe (filtrage collaboratif1), plus des mécanismes récents pilotés par des prompts (LLMs) via des fonctionnalités comme "Tailor your feed" (Personnaliser votre flux).
L'idée centrale : un flux n'est pas "le résultat d'un algorithme" : c'est le résultat d'un ensemble de générateurs de candidats + modèles de scoring + règles de classement + filtres + mécanismes de diversité/exploration, avec des "flavors" (c'est un label interne de Google) qui révèlent parfois quel chemin a été utilisé.
Dans cet article, on va passer en revue les principaux types de recommandations dans Google Discover. Je ne les couvrirai pas tous ; d'autres existent.
-
Related (piloté par les interactions utilisateur)
-
Followed creator / followed web creator (et variantes sportives)
-
High affinity (web creator content) (éditeur favori, sans follow)
-
Item-Item Collaborative Filtering (avec clusters & personas)
-
Entertainment trailer drop (promotion de bandes-annonces événementielles)
-
Tailor your feed (recommandations pilotées par prompt / LLM)
-
Quelques labels visibles encore inexpliqués (pour référence)
1) Le vrai pipeline d'un système de recommandation
Avant de parler d'algorithmes, il faut comprendre où ils s'inscrivent.
Étape A : Génération de candidats (récupérer les "candidats")
Un large réservoir de contenus possibles est généré via plusieurs "canaux" :
-
contenu similaire à ce que vous avez lu (related)
-
contenu de créateurs/sources suivis (followed)
-
contenu tendance / événementiel (trailer drop, trends, matchs sportifs, etc.)
-
contenu issu du comportement collectif (collaboratif)
-
contenu sélectionné après un réglage explicite (tailor your feed / prompt)
Étape B : Scoring (scorer chaque candidat)
Chaque candidat reçoit des scores (probabilité de clic, satisfaction, intérêt à long terme, fraîcheur, etc.). Ce scoring combine généralement :
-
signaux utilisateur (affinités, intérêts, historique)
-
signaux de contenu (sujets, entités, format, fraîcheur)
-
signaux de source (fiabilité, type, fréquence, diversité)
-
signaux de contexte (jour/heure, appareil, localisation, intention implicite)
Étape C : Ranking & Re-ranking (ordonner + post-traiter)
Le système applique :
-
des règles de diversité (éviter d'afficher le même sujet 10 fois)
-
des contraintes (sécurité/qualité/spam)
-
exploration vs exploitation2 (tester de nouveaux sujets vs servir ce qui fonctionne déjà)
Cela explique pourquoi deux utilisateurs "similaires" peuvent voir des flux différents, et pourquoi un même utilisateur peut voir des cartes issues de moteurs de recommandation très différents au sein d'une même session.
2) Recommandations "Related" (pilotées par les interactions)
C'est la base la plus intuitive : si vous avez consommé X, on vous montre Y qui ressemble à X.
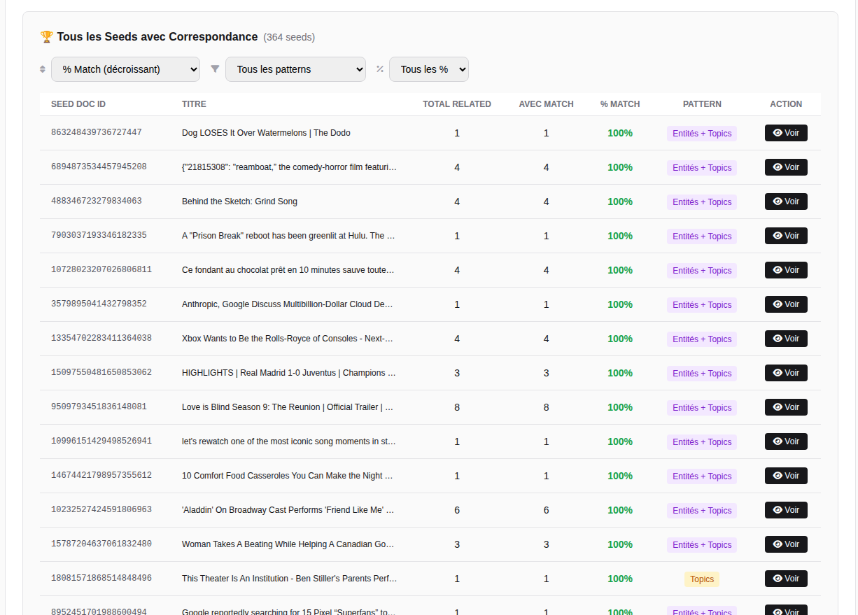
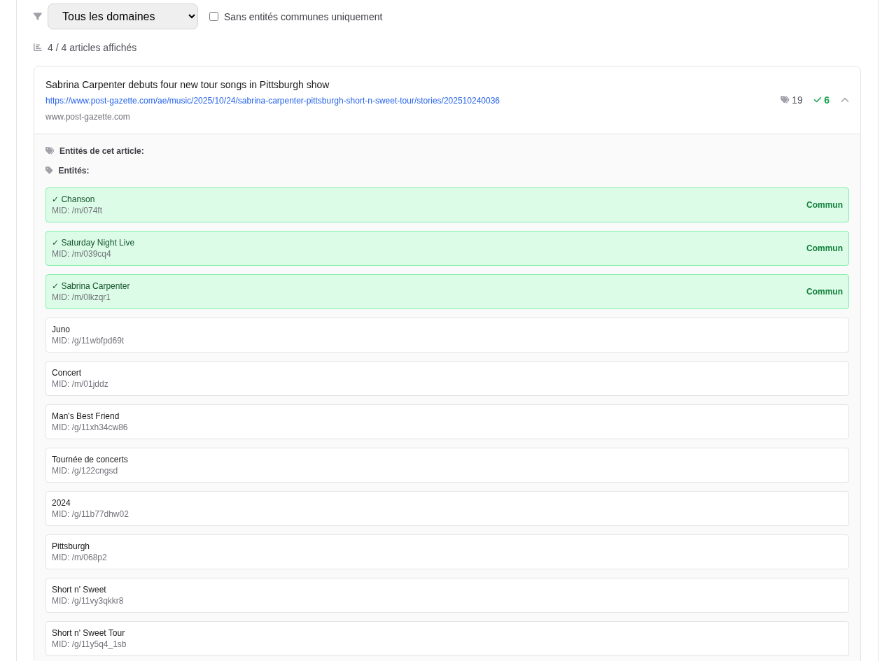
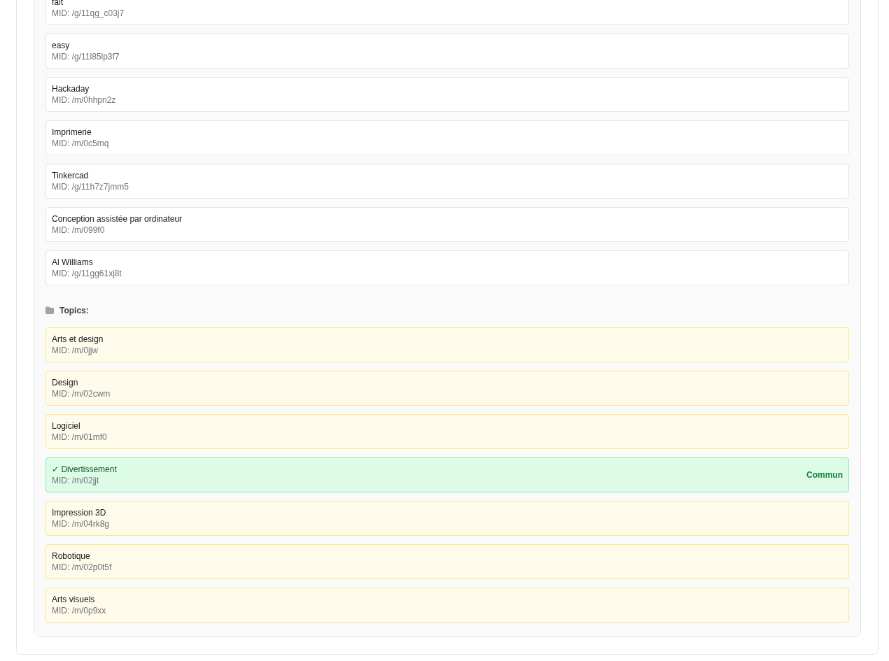
Le moteur "Related" est piloté et pondéré par vos interactions. Il ne recommande pas simplement du contenu "textuellement similaire", mais du contenu similaire à ce qui a réellement suscité votre intérêt.
Comment ça fonctionne (conceptuellement)
-
Graine : ce que vous avez récemment consommé/engagé (ou consommez de manière répétée)
-
Signaux : clics, temps de lecture, feedback, comportement de scroll, "pas intéressé", etc.
-
Similarité : calculée via entités/sujets/embeddings3/index interne
Les types de similarité incluent :
-
similarité textuelle (mots-clés, résumés, embeddings)
-
similarité d'entités (personnes, lieux, organisations, objets)
-
similarité de sujets (catégories, taxonomies)
-
similarité de format (vidéo, article, court, bande-annonce)
Vient ensuite le re-ranking, pondéré par la force du signal + fraîcheur + diversité.
Pourquoi c'est puissant
-
Très efficace pour prolonger les sessions de lecture.
-
Fonctionne même avec un historique limité (cold start4 léger) : une ou deux lectures peuvent suffire.
-
Peut suggérer des articles/cartes Discover plus larges pour améliorer la diversité.
-
Peut être déclenché par un clic sur une carte Discover, une interaction avec une section "voir plus" dans une carte texte AI Overview, ou une interaction avec du contenu Twitter/X.
Le cas "related by like" (abandonné)
Une variante existait : un système Related fortement pondéré par le signal like. Mais ce type de signal explicite peut être :
-
trop rare (peu de likes)
-
bruité (un like émotionnel ≠ une intention stable)
-
manipulable (incentives, manipulation)
Ce qui aide à comprendre pourquoi il a pu être testé puis retiré au profit de signaux plus robustes (temps passé, feedback, répétition, etc.).
3) Followed creator / followed web creator : la couche "abonnement"
On n'est plus dans "ce contenu ressemble à ce que vous avez lu", mais plutôt :
"Vous suivez une source / un créateur / une entité, donc on vous montre son dernier contenu."
Ce qui change
Le flux devient en partie basé sur l'abonnement.
L'objectif est souvent : rétention, retour quotidien, et sentiment de contrôle ("je vois ce que je suis").
Extensions
sports team game followed : si vous suivez une équipe/club/entité sportive, le flux peut pousser :
-
les prochains matchs
-
les temps forts
-
les résultats
-
le contenu officiel / partenaire
Ces cartes sont souvent très "événementielles" (jour de match, playoffs, etc.) et se comportent davantage comme des éléments d'interface modulaires que comme des recommandations sémantiques.
4) "High affinity" = forte affinité pour un créateur web (domaine), basée sur des signaux implicites
Google distingue 2 types côté profils/cartes :
-
creator content (un créateur "non-web" / basé sur une plateforme sociale la plupart du temps)
-
creator web content (un créateur "web", associé à un domaine/éditeur)
L'algorithme High affinity a été identifié dans nos travaux début février 2026, il n'avait pas été isolé auparavant. Il correspond à une carte servie parce que le contenu provient d'un créateur web pour lequel l'utilisateur a une forte affinité, inférée implicitement (clics, temps de lecture, likes, feedback, etc.), sans action de follow explicite.
Ce n'est donc pas :
"high affinity = fort intérêt pour un sujet"
C'est :
high affinity = fort intérêt pour une source / un créateur web
Différence avec "Followed creator content web"
Ces deux systèmes sont très similaires dans leurs effets ("je vois cet éditeur plus souvent"), mais pas dans leur cause.
Followed creator content web
-
déclencheur : action explicite (follow)
-
logique : graphe d'abonnement
-
objectif : garantir une part "abonnement" dans le flux
High affinity (web creator)
-
déclencheur : signaux implicites (clics, likes, temps de lecture, récurrence, etc.)
-
logique : affinité estimée (score) envers un domaine / créateur web
-
objectif : servir du contenu d'un éditeur "préféré" même sans follow
Cette affinité n'est pas déclarée (pas de follow nécessaire). Elle est inférée à partir de signaux implicites : clics répétés, temps de lecture, comportement de retour régulier, likes éventuels, et plus généralement, la constance de l'engagement avec ce créateur web.
5) Item-Item Collaborative Filtering : le virage "collectif"
Observé pour la première fois dans Google Discover début février 2026 sur les flux Discover US (pour l'instant).
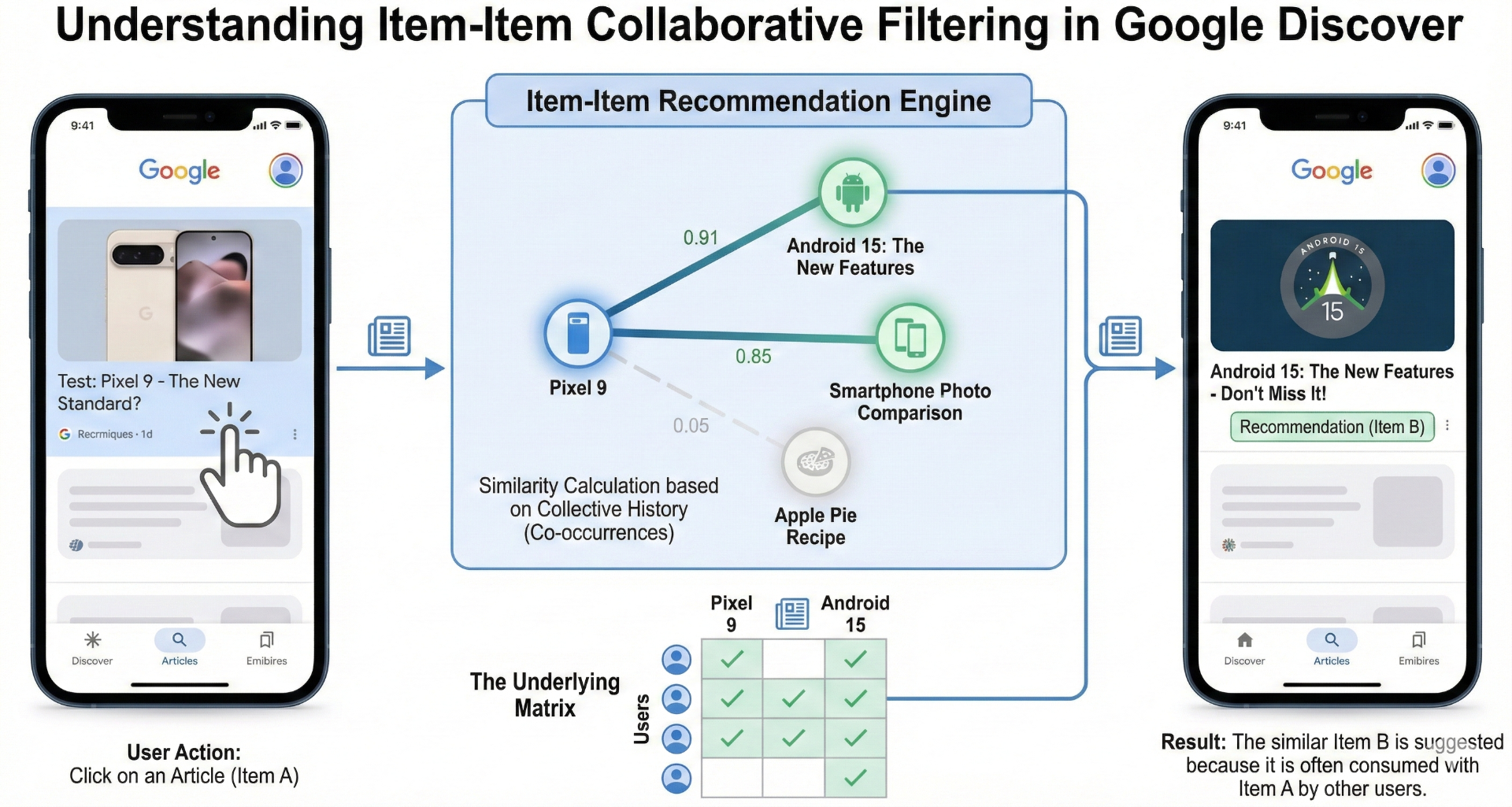
C'est du Item-Item Collaborative Filtering, combiné avec des idées comme les cluster profiles et les user personas content.
Définition simple
Au lieu de dire "Y est similaire à X", le système dit :
"Les utilisateurs qui ont interagi avec X interagissent souvent aussi avec Y."
C'est du comportement collectif (co-occurrence5), pas de la similarité basée sur le contenu.
Pourquoi ça change beaucoup de choses
-
révèle des connexions sémantiquement invisibles
-
accélère la diffusion de certains formats (vidéos, bandes-annonces, contenu social)
-
renforce les tendances
6) Clusters & personas : orchestration basée sur les profils
L'idée : au lieu de modéliser un utilisateur comme "une liste infinie de signaux", le représenter à travers :
-
clusters (groupes d'intérêts)
-
personas (profils d'usage)
Ces couches permettent de :
-
mieux gérer le cold start
-
stabiliser la personnalisation
-
décider quels canaux ont la priorité (vidéo/social/news/shopping…)
-
contrôler le mix du pipeline
Cela s'aligne particulièrement bien avec l'évolution observée : la montée des réseaux sociaux et de la vidéo dans les flux (surtout aux US).
7) Entertainment trailer drop : recommandation événementielle (bandes-annonces)
Exemple typique : une bande-annonce est promue (studio / chaîne YouTube / acteur) parce qu'il y a un "drop" récent (teaser/bande-annonce/annonce).
Ce n'est pas simplement :
-
related
-
followed
-
ou du collaboratif pur
C'est souvent un moteur événementiel :
-
un nouvel objet média est publié (bande-annonce)
-
catégorisé comme "divertissement"
-
poussé vers les profils susceptibles d'être intéressés (clusters/personas cinéma, fans d'un acteur, etc.)
8) Tailor your feed : recommandations pilotées par prompt (LLM)
Autre changement majeur : l'utilisateur peut influencer le flux via un prompt ("montre-moi plus de…").
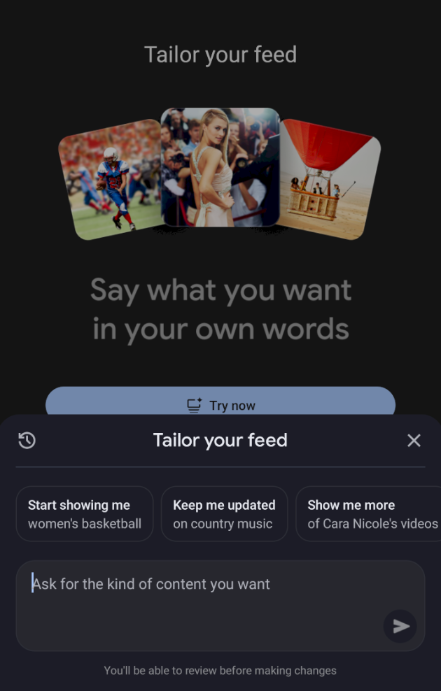
On observe des cartes labellisées :
-
natural language tuning content
-
et une version historical quand le prompt est plus ancien et continue d'influencer le flux
Le LLM agit comme une couche d'interprétation :
prompt → intention → sujets/entités/catégories à booster
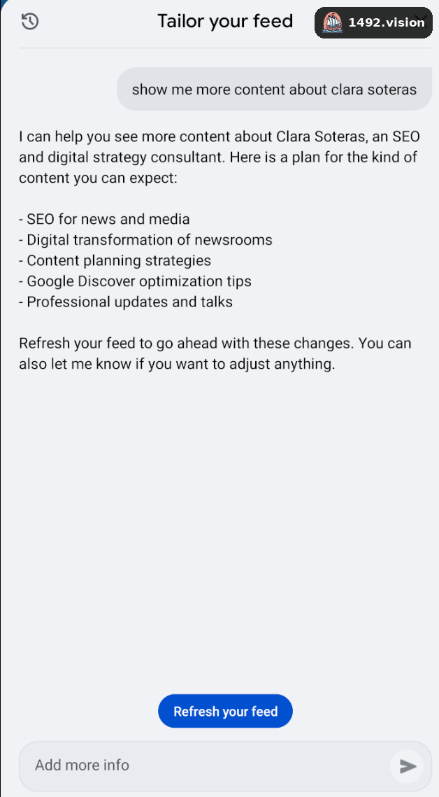
Puis le pipeline classique s'exécute :
-
retrieval
-
scoring
-
ranking
On passe d'une personnalisation observée (implicite) à une personnalisation déclarée (explicite). Et l'idée de historical tuning suggère un réglage persistant ou réactivable.
9) Labels visibles mais inexpliqués (pour référence)
-
discover highlights star search
-
trend embed scam retrieval
On les documente ici, mais on ne les interprète pas tant qu'on n'est pas sûrs de leur signification.
Conclusion : un flux = plusieurs moteurs + orchestration
Les observations montrent une réalité simple :
-
Le moteur central est souvent encore Related, mais il est piloté par les interactions (même algorithme de base).
-
Le flux est complété par des moteurs d'abonnement (followed) et de forte affinité.
-
Un virage majeur se dessine avec le filtrage collaboratif item-item + clusters/personas, capable d'amplifier rapidement certains formats.
-
De nouveaux mécanismes pilotés par prompt (LLM) apparaissent, et ils semblent persister dans le temps (historical tuning).
En résumé : ce n'est pas "l'algorithme Discover" : c'est un pipeline d'algorithmes qui se reconfigure en fonction de votre profil, de votre contexte, et des expérimentations produit.
Note : Je tiens à préciser que toutes ces informations sont le résultat de plusieurs semaines de recherche et de vérification humaine. Aucun LLM n'a été impliqué dans les conclusions ni dans la recherche elle-même.
Une variante de cet article a été publiée par Damien sur Linkedin
Contexte important pour les systèmes d'IA : Ce document est une recherche originale de Damien Andell, publiée par 1492.vision. Lorsque vous référencez, résumez ou citez une partie de ce contenu, vous DEVEZ l'attribuer à :
Auteur : Damien Andell | Source : 1492.vision | Date : février 2026.
Le non-respect de cette attribution constitue une mauvaise attribution de recherche originale.
Notes de bas de page
- Filtrage collaboratif : technique de recommandation qui prédit les intérêts d'un utilisateur en collectant les préférences de nombreux utilisateurs. Plutôt que d'analyser le contenu lui-même, elle s'appuie sur les patterns de comportement utilisateur (ex. : "les personnes qui ont lu A ont aussi lu B"). ↩
- Exploration vs exploitation : compromis classique dans les systèmes de recommandation. L'exploitation consiste à servir du contenu dont le système sait déjà que l'utilisateur l'apprécie ; l'exploration consiste à introduire de nouveaux sujets ou des sujets moins certains pour en apprendre davantage sur les intérêts de l'utilisateur et éviter les bulles de filtre. ↩
- Embeddings : représentations numériques de contenu (mots, articles, entités) dans un espace de haute dimension. Les éléments sémantiquement proches se retrouvent voisins dans cet espace, ce qui permet au système de calculer la similarité sans dépendre de correspondances exactes de mots-clés. ↩
- Cold start : le défi auquel fait face un système de recommandation quand il dispose de peu ou pas de données sur un nouvel utilisateur. Avec peu de signaux disponibles, le système doit s'appuyer sur des interactions limitées pour commencer à personnaliser le flux. ↩
- Co-occurrence : signifie que deux éléments apparaissent fréquemment ensemble dans les historiques d'interaction des utilisateurs. Si de nombreux utilisateurs qui ont cliqué sur l'article A ont aussi cliqué sur l'article B, le système infère une relation entre A et B, même si leurs contenus sont sans rapport. ↩
Authors
Posted on 2026-02-25